Figure A.1: lazarus uncovering a deleted image.
The Coroner's Toolkit is a collection of forensic utilities by Wietse Venema and Dan Farmer [Farmer and Venema, 2004]. The software was presented first in 1999, in a one-day forensic analysis class at the IBM T.J. Watson Research Center. The first general release was in 2000, via the author's websites. The software was extended in various ways by Brian Carrier, who makes his version available as the Sleuth Kit [Carrier, 2004a]. This appendix presents an overview of TCT and of some of its extensions.
The grave-robber command collects forensic information. This tool can be used either on a "live" victim machine, or on a disk image from a victim's file system. In "live" collection mode, grave-robber aims to respect the Order Of Volatility (see Appendix B). It uses many of the utilities that are part of TCT to collect information in the following order:
The attributes of all the commands and files that TCT accesses while it gathers information. These are collected first in order to preserve their MACtime attributes.
Process status information, and optionally, the memory of all running processes.
Deleted files that are still active.
The executable files of all processes.
All attributes from deleted files.
Network status information.
Host status information, via system dependent commands that provide system configuration information.
Attributes of existing files; this produces the body file that is used by the mactime tool as described below.
Optionally, security sensitive information that is under control by users of the system, such as files that grant remote access to a user's account, and cron jobs for unattended command execution on behalf of users.
Copies of configuration files and other critical files.
All this information is stored in a "vault", a protected directory structure that is named after the host and the time of the start of data collection. For each file that is stored into the vault, grave-robber also computes the MD5 hash. At the end, as the vault is closed, grave-robber computes the MD5 hash over all individual file hashes.
By definition, grave-robber is exposed to information that comes from the untrusted victim machine. It frequently uses this information while executing TCT commands and system commands. While doing so, it takes great care to never expose that untrusted information to a shell command interpreter. For more of the philosophical issues behind grave-robber, see Appendix B.
The mactime command takes file attribute information from a body file that was produced by grave-robber, and produces a chronological report of all file access methods by file name. Alternatively, mactime can generate a body file on the fly while it scans a file system. This tool was written several years before the authors started work on the TCT, and was adapted to fit into the grave-robber framework. mactime is introduced in chapter 2, "Time machines", and a larger example can be found in chapter 4, "File system analysis".
As an example of the kind of insight that mactime can give, listings A.1 and A.2 present different views of the same remote login session. The first shows what the remote user sees, and the second shows the corresponding MACtime report. For educational reasons the example uses a very old machine so that the MACtimes are spread out over time. This allows us to see a clear separation between the start-up of the telnet server and login software, the access of system files while the user logs in, and the start-up of the user's login shell process.
$ telnet sunos.fish.com Trying 216.240.49.177... Connected to sunos.fish.com. Escape character is '^]'. SunOS UNIX (sunos) login: zen Password: Last login: Thu Dec 25 09:30:21 from flying.fish.com Welcome to ancient history! $Listing A.1: User view of a remote login session.
Time Size MAC Permission Owner Group File name 19:47:04 49152 .a. -rwsr-xr-x root staff /usr/bin/login 32768 .a. -rwxr-xr-x root staff /usr/etc/in.telnetd 19:47:08 272 .a. -rw-r--r-- root staff /etc/group 108 .a. -r--r--r-- root staff /etc/motd 8234 .a. -rw-r--r-- root staff /etc/ttytab 3636 m.c -rw-rw-rw- root staff /etc/utmp 28056 m.c -rw-r--r-- root staff /var/adm/lastlog 1250496 m.c -rw-r--r-- root staff /var/adm/wtmp 19:47:09 1041 .a. -rw-r--r-- root staff /etc/passwd 19:47:10 147456 .a. -rwxr-xr-x root staff /bin/cshListing A.2: MACtime view of the listing A.1 remote login session. The MAC column indicates the file access method (Modify, read Access, or status Change). Files names with the same time stamp are sorted alphabetically.
As discussed in chapters 3 and 7, modern file systems minimize file access times by keeping related information closely together. Among other things, this reduces the fragmentation of individual files. The TCT program lazarus takes advantage of this property when attempting to reconstitute the structure of deleted file content.
lazarus is a simple program whose goal is to give unstructured data some form that is both viewable and manipulatable by users. It relies on a few simple principles and heuristics:
All popular file systems divide their storage space into equal-sized blocks. Typical block sizes are 1024 bytes and 4096 bytes. As long as lazarus uses an input block size that is consistent with this, it will never miss an opportunity for dividing up a file appropriately.
File systems like to avoid file fragmentation performance reasons. In particular, UNIX file systems tend to be relatively fragmentation free even after years of use.
Files often have a distinct signature at the beginning. The venerable UNIX file utility uses a database with patterns to recognize files by the signature of their content. lazarus uses this in addition to a built-in pattern matcher to recognize file headers and to classify other file content.
If a disk block looks similar to the previous disk block, then lazarus assumes that both blocks are part of the same file.
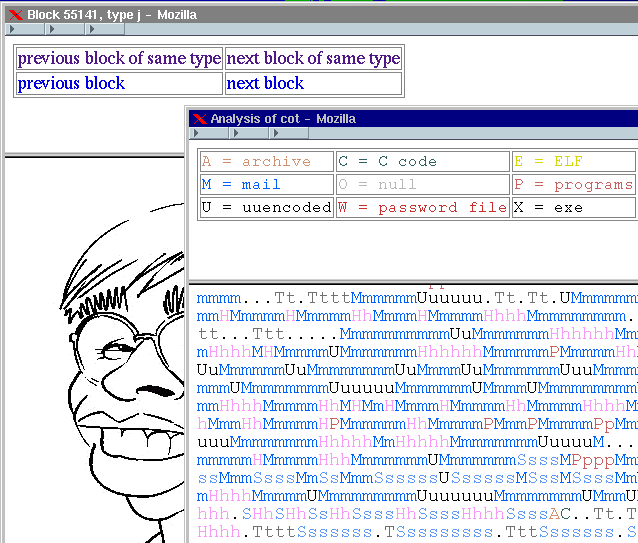
With these in mind lazarus implements a sort of primitive digital X-ray device. It creates a map of the disk that essentially makes the drive transparent -- you can peer into the disk and see the data by content type, but the highly useful filesystem abstraction is lost. Figure A.1 shows an example of the interface and a once-deleted image file.
Figure A.1: lazarus uncovering a deleted image.
In the map of a disk, lazarus uses simple text characters to represent data chunks. A capital letter is used for the first block of a chunk, while lower case is used for its remainder. For example, "C"'s represent C source code, "H"'s are hypertext, "L"'s are log files, "M"'s mail, "U"'s uuencoded content, and "."'s unrecognized binary data.
In order to keep the map manageable, lazarus compresses large chunks using a logarithmic (base 2) scale. This means a single character is 1 block of data, the second character 2 blocks, the third 4, etc. This allows large files to be visually significant but not overwhelming - with a 1024 byte block size, a megabyte file would only take up ten times the space of a single block file.
lazarus demonstrates that UNIX file systems like to keep related information within the same file system zone. For example, figure A.1 shows that email files (indicated with "Mmmm") tend to be clustered together. The figure also shows that email with lots of hypertext or uuencoded content is likely to be mis-identified. The clustering of files and file activity has important consequences for the persistence of deleted information, as we see in chapter 7, "Persistence of Deleted File Information".
Software such as lazarus presents a problem of non-trivial scope. While lazarus takes care to neutralize active content in hypertext etc. by rendering it as plain text, it does no sanity checks on other data such as images, and may trip up bugs in a very large and complex web browser program.
lazarus has not evolved since its initial release. People who want to browse disks should consider using Brian Carrier's Autopsy tool [Carrier, 2004b].
The TCT comes with a number of utilities that bypass the file system layer. This allows the software to access existing file as well as deleted file information. Instead of file names, these programs use the abstraction of inode numbers and bitmap allocation blocks, or the even lower-level abstraction of disk block numbers. These lower-level concepts are introduced in chapter 3, "File system basics".
The TCT supports popular UNIX file systems such as UFS (BSD and Solaris), and EXT2FS and EXT3FS (Linux). The Sleuth Kit also adds support for non-UNIX file systems such as NTFS, FAT16 and FAT32 (Microsoft Windows).
Utilities that are part of the original TCT distribution:
ils Access file attributes by their inode number. By default, this lists all unallocated file attributes.
icat Access file content by their inode number. This is used primarily to look up deleted file content.
unrm Access disk blocks by their disk block number. By default, this reads all unallocated file content, and produces output that can be used by programs such as lazarus. In the Sleuth Kit distribution, unrm is renamed to dls.
The Sleuth Kit adds a number of other low-level utilities, such as:
ffind Map an inode number to the directory entry that references the inode.
fls List directory entries, including deleted ones. Section 4.14 shows an example of the use of this utility.
ifind Map a data block number to the inode that references the data block.
The success rate of low-level file system tools with deleted file information is highly dependent on the file system type, and even on the version of the operating system software. Section 4.11, "what happens when a file is deleted", discusses how much information is lost and what is preserved when a file is deleted.
The tools described in this section are more for exploratory use than rock-solid analysis. The reason for this is that their output contains little or no structural meta information, so that it is suitable only for processing with tools that don't take advantage of such information.
pcat Dump the memory of a running process. This program is used in section 2.6; other examples of its use can be found on the book's website.
memdump Dump system memory while disturbing it as little as possible. The output should be sent across the network, in order to avoid interaction with the content of the file system cache. This program is used for some of the measurements in Chapter 8.
[Carrier, 2004a] Brian Carrier's Sleuth Kit.
Available from: http://www.sleutkit.org/
[Carrier, 2004b] Brian Carrier's Autopsy Forensic Browser.
Available from: http://www.sleutkit.org/
[Farmer and Venema, 2004] The Coroner's Toolkit software by
Dan Farmer and Wietse Venema.
Available from:
http://www.fish2.com/tct/
and http://www.porcupine.org/tct/