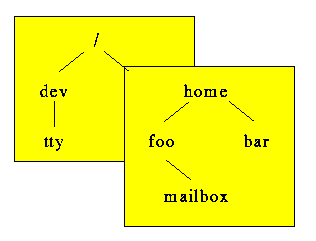
Figure 3.1: UNIX file system tree built from multiple disk partitions.
In this chapter we will explore some fundamental properties of file systems. As the primary storage component of a computer the file system can be the source of a great deal of forensic information. We'll start with the basic organization of file systems and directories, including how they may be mounted on top of each other to hide information. We'll then move onto various types of files along with their limits and peculiarities, as well as the basic inode and data block relationship. Next we outline the lowest levels of the file system - partitions, zones, inode and data bitmaps, and the superblock. Along the way we'll discuss and introduce a variety of tools and methods to facilitate our exploration and analysis.
It is important to note that forensic data must be captured at the appropriate abstraction level. For example, tools that use the normal file system interface will only be able to access existing files. In order to capture information about the unused space that exists between files, one has to use lower-level tools that bypass the file system. Such lower-level tools have additional benefits: they eliminate the possibility of false reports by maliciously modified file system code. This chapter will lay the groundwork to go into more serious analysis in the following chapter, "File System Analysis."
There are more file systems than there are operating systems. Microsoft has several and UNIX certainly has its share, in typical acronym fashion: FFS, UFS, Ext2fs 1, XFS, etc. Much has been written about these [McKusick, 1984], [Card, 1994], [Nemeth, 2002], and others), and we aren't trying to write the definitive or complete file system reference. The purpose of this chapter is to illustrate general file system properties and their relevance to forensic analysis, irrespective of their origin. However, to keep the discussion succinct we'll focus on file systems that are either based on or very similar to the UNIX Fast File System (FFS). The FFS was well-designed and has a fairly easy to understand design that has influenced many other file systems.
Footnote 1: Ext3fs is Ext2fs with journaling added. While there are other differences, for this chapter on basics we will treat them as the same, and you may replace Ext3fs for Ext2fs in the text wherever desired. See section 2.8, "Journaling file systems and MACtimes", for more on file system journaling.
The original UNIX file system dates back to the early days of UNIX evolution. While many improvements have been made in the course of time, the fundaments of the design have not changed in 30 years. That is amazing, considering that disk capacity has increased by a factor of ten thousand, and it means that the initial design was done by very smart people ([Ritchie, 1974]).
In order to make files on a disk partition accessible, the disk partition has to be mounted at some directory in the file system tree. As figure 3.1 demonstrates, when a disk partition is mounted over a directory its contents overlay the directory it is mounted over, much like roof tiles overlap each other.
Figure 3.1: UNIX file system tree built from multiple disk partitions.
You may mount many different types of file systems on top of each other - not only the UNIX standards but also those accessed across the network (NFS, AFS, etc.) and from completely different vendors (Microsoft, Apple, etc.) and operating systems. Unfortunately, while all these file systems will behave somewhat as standard UNIX file systems, this beauty is sometimes only skin deep. When mounted onto UNIX you'll sometimes only get a subset of the Microsoft, Apple, etc. semantics. The network abstraction will usually strip off even more lower-level details of the file system. You can even mount files containing block file system formats onto special devices (such as the loopback file or vnode pseudo disk device drivers, which we'll talk about in Chapter 4: File system analysis.)
Disks can contain many file systems, and the file system tree can be built from multiple disk partitions. Note that the tiling effect mentioned above means that you can hide things underneath a mount point. Here df shows the mounted file systems before and after a file system is stacked on top of the "/research" directory and how the contents of a file underneath a mount point cannot be read with cat.
# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/sda1 1008872 576128 381496 60% / /dev/sda5 16580968 15136744 601936 96% /home # ls /research foo # cat /research/foo hello, world # mount /dev/sdb1 /research # ls /research lost+found src tmp # cat /research/foo cat: /research/foo: No such file or directory
The file system provides little if any help when you want to know about details of where and how it stores information; indeed, the entire purpose of file systems is to hide such detail. In order to look under the file system, you have to bypass the file system code and use tools that duplicate some of the file system's functionality.
If a mounted file system isn't currently being used the umount command may be used to remove it from the directory tree. File systems are called busy and cannot be unmounted when they contain files that are currently open or have running processes whose current directory or executable file is within the file system. You may try to force the file system to unmount under Solaris, FreeBSD, and Linux by using umount's -f option, but this can crash processes that have their virtual rug pulled from underneath them. The fuser or lsof commands may be used to determine which processes are preventing us from unmounting a busy file system. In the next section we'll also reveal how to peer under mount points when we discuss inodes in more detail.
Another fine way to conceal information is not by ensconcing it under another file system, but to simply neglect to mount the file system at all, so that it doesn't appear in the directory structure. There is no easy way to find all the file systems (or hardware in general) that may be attached to a system - especially since they may not be even turned on while you're examining the computer. Being in the same physical location as the computer is helpful (so you may see the devices in question), but with components getting smaller every day (e.g. keyboards and mice with USB or memory sockets) even this is not a foolproof solution.
However, a UNIX computer will usually record the existence of hardware attached to it as it boots to a ring buffer of kernel memory. (It's called a ring because the buffer will overwrite older messages with more recent entries as the buffer is filled.) Linux and FreeBSD, as well as older versions of Solaris, have the dmesg command to print out this buffer. (With recent Solaris versions, the dmesg command displays information from system logfiles that are updated by syslogd.) While the records vary from system to system you may get valuable information by pouring over this record - see listing 3.1 for an illustration of this.
freebsd# dmesg [...] ppi0: <Parallel I/O> on ppbus0 ad0: 114440MB <WDC WD1200JB-75CRA0>[232514/16/63] at ata0-master UDMA100 ad1: 114440MB <WDC WD1200JB-75CRA0>[232514/16/63] at ata0-slave UDMA100 ad3: 114473MB <WDC WD1200BB-00CAA0>[232581/16/63] at ata1-slave UDMA33 acd0: CDROM <LTN526S>at ata1-master PIO4 Mounting root from ufs:/dev/ad0s2a /dev/vmmon: Module vmmon: registered with major=200 minor=0 tag=$Name: build-570$ /dev/vmmon: Module vmmon: initialized [...]Listing 3.1: Elided dmesg output, displaying three hard disks and a CDROM on a FreeBSD system. It also shows the capacity of the disks, potential mount points, and additional miscellaneous information.
After the system has completed its startup phase, newly added hardware will be reported to the ring buffer, or cause the UNIX kernel to log a message via the syslogd (Solaris and FreeBSD) or klogd (Linux) daemons. Keeping an eye on dmesg or these log files can be the only indication that the configuration has changed.
FreeBSD and Linux also have the fdisk command (each, of course, with its own set of options), which displays any partitions on a given disk, while Solaris' prtvtoc command prints out a disk's geometry and partitions contained in the VTOC (volume table of contents.)
In the following example, df shows what file systems are mounted, while fdisk uncovers a hidden Linux partition named /dev/sda5:
linux# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/sda1 1008872 576128 381496 60% / linux# fdisk -l /dev/sda Disk /dev/sda: 64 heads, 32 sectors, 17501 cylinders Units = cylinders of 2048 * 512 bytes Device Boot Start End Blocks Id System /dev/sda1 * 1 1001 1025008 83 Linux /dev/sda2 1002 17501 16896000 5 Extended /dev/sda5 1002 17452 16845808 83 Linux
We can then mount the hidden file system and explore its contents.
linux# mount /dev/sda5 /mnt linux# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/sda1 1008872 576128 381496 60% / /dev/sda5 16580968 15136744 601936 96% /mnt
We'll talk about how to capture file system data in chapter 4, "File System Analysis."
This flexibility can cause problems with unprepared programs that trust the input they receive to be well-behaved. For instance, the touch command can create a file name with a newline character embedded in it:
$ touch '/tmp/foo /etc/passwd'
If such a file name exists and someone with root privileges was foolish enough to try this housekeeping command (which attempts to remove files in the temporary directory that were modified a day or more ago):
# find /tmp -mtime +1 | xargs rm -f
The password file would be deleted, probably not what was wanted. This example mirrors a bug that was found in several UNIX distributions. Cron, the program that allows users to schedule periodic execution of programs, had just such a command that was executed with super-user privileges. Because of this problem many implementations of find and xargs now include an option (usually "-print0" or "-0") to separate file names by a null character, which should be relatively safe since nulls, as previously noted, cannot be in a file name.
These size limits for directories and files names are rarely a concern for day to day operations, but they give opportunities to hide information or to prevent programs from working. For instance, this file (with a complete pathname length of 1028 bytes, composed of four directories of 255 characters each with the actual file name of "foo"):
This file is a tricky one to access in both Solaris or FreeBSD (and if the file name were a bit longer this would be true for Linux as well); you cannot specify the full pathname because its length is above the limit that you may use in a system call such as open. For the same reason you cannot directly change into a very long directory pathname, because the chdir system call is subject to the same pathname length restriction as other system calls./111 ... 111/222 ... 222/333 ... 333/444 ... 444/foo
Programs like find suffer from limits that are imposed by their environment. Even without hard limits built into the software itself, such programs will ultimately fail when the directory tree is sufficiently deep, as the system runs out of memory to keep track of nesting or out of file descriptors for reading directories.
The basic problem is not that UNIX allows long file names and deeply nested directory trees, but that you - as a programmer or a user - should be wary of trusting anything outside your sphere of control. When investigating a system it is important to understand how the system and your tools will behave under stress or unusual circumstances. All tools have a breaking point - good ones will fail gracefully and inform you of the failure and the reasons why. When in doubt always exercise extreme diligence and caution.
From the user point of view, the UNIX file system is made up from directories and an assortment of files of various types. To UNIX, however, a directory is just another type of file, one that ordinary users cannot modify directly. On a typical UNIX system you will find regular files, directories, symbolic links, IPC endpoints, and device files.
Regular files
Regular files are the most common type of file on a UNIX system and are the kind of file that contains data or software.
Directories
Directories are another type of file, but users cannot update a directory directly. Instead this is done via primitives that create, rename or remove a directory entry.
A directory contains all the names of files and directories within it; the basic ls(1) command is therefore easy to understand - or code - even if you know nothing about the underlying low-level details. You simply open the directory (via the opendir() function) and read the contents with the readdir() system call. The Perl program in listing 3.2 does just that.
$ cat ls.pl
#
# Usage: "program [directory-name]"
#
# Defaults to reading the current directory unless we give it an argument
#
$ARGV[0] = "." unless $#ARGV >= 0;
opendir(DIR, $ARGV[0]) || die "Can't open directory $ARGV[0]\n";
# read the directory, one file name at a time, and print it out
while (($next_file = readdir(DIR))) {
print "$next_file\n";
}
$
$ perl ls.pl /tmp
.
..
ps_data
ups_data
Listing 3.2: Trivial "ls" command which prints out a directory's entries
Symbolic Links
A symbolic link is an alias for another file name or directory. Simply removing a symbolic link doesn't affect the file being referred to, but be aware that any output directed at the symbolic link will affect the target, not the symbolic link.
IPC (Inter-Process Communications) Endpoints
IPC Endpoints in the file system 1 allow one process to talk to another process running on the same machine. A FIFO (also called named pipe) may be created with the mkfifo() system call, and provides a one-way communication channel, while a socket is created with the socket() system call and provides a two-way channel each time a connection is made.
Footnote 1: As opposed to other IPC endpoints, such as Internet sockets.
Named pipes can be trouble if they aren't connected to any data stream, for a process that attempts to read the contents of the named pipe will hang, waiting for data.
Device Files
UNIX uses device files to access hardware. The two types - character and block - give access to device drivers that control disks, terminals, and so on. Typically, they are found below the /dev directory, are created with the mknod command, and are protected via the same file system permission bits as other files.
Block devices access the hardware via the block structure that the physical medium uses, and use buffering in the kernel. Disks are the primary example of a block device. Character devices can use (generally smaller) buffers as well, but allow byte level access (either virtual or real) to hardware, and are not buffered as block devices are. Terminals, line printers, and physical memory are some of the more common character devices, but many block devices also have a character-device interface. Disk and tape character devices are called raw devices, and they are not buffered in the kernel.
The interface between hardware and software can cause a variety of problems. When a device has both a character and block device interface you may run into trouble when trying to access data through character device since the kernel is buffering the data and may not have written it to the actual device. We'll show an example of this in the next section. Device files may also be duplicated and placed anywhere on a file system - users that have system privileges may place a normally restricted device in an unusual or hidden location with weaker than desired file permissions. The FreeBSD and Linux mount command has a "nodev" option which forbids access to block or character device files. Care must be also be taken when memory-mapped devices are present on the system (such as when registers in graphics cards are mapped to the virtual address space to provide faster performance), for probing or searching these memory locations (say, via /dev/mem or /dev/kmem, or TCT's pcat command; see appendix A for more about TCT and the tools within) can cause the system to freeze or even crash.
In order to discuss the more unusual properties of the UNIX file system it is necessary to peel back its outer layer and examine some of its file system internals.
A UNIX directory is organized as a sequence of directory entries that are not necessarily sorted. Each directory entry consists of at least two parts: a name and a number. Directory entries in Ext2fs and modern FFS file systems also list the file type, unlike Solaris' UFS. The file name is what humans and programs normally use in order to access a file. The number refers to a file's inode, and is what UNIX uses internally. This number is an index into a table of so-called inode blocks that describe all file properties except the file name. The inode block has references to the data blocks that contain the actual contents of the file. Figure 3.2 illustrates these relationships.
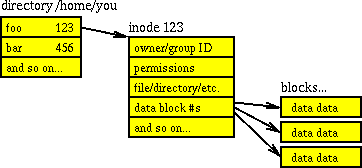
Figure 3.2: Simplified structure of the UNIX file system.
The inode itself contains a wealth of information about a file; at a minimum it includes:
Some UNIX versions allow unprivileged users to change the ownership of files that they own to another user. This rather dangerous practice is disallowed in FreeBSD and Linux systems altogether, but the POSIX RSTCHOWN parameter can be used in Solaris and other systems to control this behavior (it is turned off by default.)
Command interpreters with set-uid or set-gid file permissions are frequently left behind by intruders as a way to regain privileged access. Always be wary of set-uid or set-gid files, but especially those that weren't installed with the vendor's operating system. The find command may be used to locate such files, but it's best to simply use the nosuid option when mounting untrusted file systems - this flag takes away the special properties of set-uid and set-gid files.
Some file systems include support for immutable or append-only bits. The former disallows changing, moving or deleting such a file, while the latter is an immutable file that also allows data to be appended to its end [McKusick, 2005].
UNIX file systems allow a file to be removed even while it is still being accessed or executed. The directory entry will be removed, but the file's inode and data blocks are still labeled as "in use" until the file is no longer needed. TCT's ils and icat may be used in conjunction to recover files that are open but have been removed.
A file can even have entries in directories not owned by the file owner. Thus, when a file is found in a directory, the file wasn't necessarily put there by the file's owner. The directory owner could have created the hard link with the ln command. It also means that a file does not necessarily go away when it is deleted! The file is deleted only when the link count is zero.
We'll be talking more about MACtimes in Chapter 4: "File system analysis".
FreeBSD and Solaris don't come with any programs to query inodes (Linux has the stat command, which prints the inode contents), but you may construct your own. The stat(), fstat(), and lstat() system calls return most of the above information, as illustrated by this Perl code fragment:
($dev, $inode, $mode, $nlink, $uid, $gid, $rdev, $size,
$atime, $mtime, $ctime, $blksize, $blocks) = lstat($filename);
print "$filename: $dev, $inode, $mode, $nlink, $uid, $gid, $rdev, $size,
$atime, $mtime, $ctime, $blksize, $blocks\n";
(Further information on specific inode information can be found in its corresponding file system header file or in the stat(2) man page.)
TCT contains two programs that delve into inodology. The ils command reads inode content, and the icat command reads the data blocks that an inode refers to. The icat command may be used exactly like cat, except that instead of accessing a file by name, icat access a file by its device name and inode number. A third tool, fls ([Carrier, 2004], lists file and directory names similar to ls. Again, instead of a pathname one specifies a device name and inode number.
All three tools bypass the file system and access disk blocks directly, and this is why they use device names and inode numbers instead of pathnames. The tools can be used not only to examine a disk partition that contains a file system, they can also be used to examine a file system image, that is, a regular file that contains the content of a disk partition. More information about how disk images are created and how they are used can be found in the next chapter.
Earlier in this chapter we showed how files could be hidden from cat under a mount point, but the dynamic duo of fls and icat will not be fooled, as they bypass the file system by utilizing a lower-level abstraction.
To demonstrate this we show two different ways to access a file. First ls reads "foo"'s directory entry to recover the file name and inode number, while cat prints the contents via the file name. Next fls and icat bypass the file system altogether to read "foo"'s inode number and contents directly.
# df Filesystem 1k-blocks Used Available Use% Mounted on /dev/sda1 1008872 576128 381496 60% / /dev/sda5 16580968 15136744 601936 96% /home # ls -1ia /research 32065 . 2 .. 96741 foo # fls -ap /dev/sda1 32065 -/d 96193: . -/d 2: .. -/r 96741: foo # cat /research/foo hello, world # icat /dev/sda1 96741 hello, world
We now mount a second file system on top of the directory file "foo" lived in. When we look again, ls and cat cannot see the file, but fls and icat have no problems peering underneath the mount point.
# mount /dev/sdb1 /research
# ls -1ia /research
2 .
2 ..
11 lost+found
32449 tmp
# fls -ap /dev/sda1 32065
-/d 96193: .
-/d 2: ..
-/r 96741: foo
# cat /research/foo
cat: /research/foo: No such file or directory
# icat /dev/sda1 96741
hello, world
As previously mentioned, directories are simply another type of file; most file systems allow direct reading of a directory (via strings or cat), but Linux requires icat or some other program to directly access its contents.
Directories mounted over the network (as with NFS) often cannot be directly accessed at all. This loss of low-level detail is one of the main reasons why forensic and other serious investigative data should always be directly gathered on the computer hosting the data rather than accessed across a network.
To further confound matters, sometimes icat won't get you what you want... but cat will! Watch what happens when we create a simple file and try to access the contents via its name versus its inode:
solaris# df Filesystem kbytes used avail capacity Mounted on /dev/dsk/c0t0d0s7 2902015 1427898 1416077 51% /export/home solaris# echo hello, world > test-file solaris# ls -i test-file 119469 test-file solaris# cat test-file hello, world solaris# icat /dev/dsk/c0t0d0s7 119469 solaris# icat /dev/rdsk/c0t0d0s7 119469 hello, world
This is all possible because of how the file system buffers data (we'll see more about this in chapter 8, "Beyond Processes"). In this case the data blocks pointed to by inode number 119469 have not been written to disk yet. Trying to access them via the raw device bypasses file system buffers, so icat sees nothing.
An interesting feature of UNIX file systems is that when an application skips over areas without writing to them the data blocks will not be allocated for this empty space. This happens when a program writes data after seeking past the end of a file; after the write this hole is read as though it was full of null bytes. The Berkeley DB (e.g. "filename.db") and DBM files (e.g. "filename.pag") files, used in USENET news history, Sendmail maps, and the like are examples of such, which are sometimes called sparse files.
To see the difference we'll use a Perl program to create two files, one with a hole and one without:
$ cat hole.pl #!/usr/local/bin/perl # Create two files, F1 & F2 open(F1, ">F1") or die "can't open F1\n"; open(F2, ">F2") or die "can't open F2\n"; # With holes print F1 "Text before test"; seek(F1, 100000, 2); # boldly seek where no data has gone before print F1 "Text after test"; # Without holes print F2 "Text before test"; print F2 "\000" x 100000; # output 100,000 NULLS print F2 "Text after test"; close(F1); close(F2);
After executing this Perl program look how ls shows the different block allocation sizes of the sparse and regular files, but when the files are run through cmp (a file content comparison program) no difference is shown.
linux $ ./hole.pl linux $ ls -ls F1 F2 12 -rw------- 1 zen root 100031 May 30 15:09 F1 104 -rw------- 1 zen root 100031 May 30 15:09 F2 linux $ cmp F1 F2 linux $ hexdump -c F1 0000000 T e x t b e f o r e t e s t 0000010 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 * 00186b0 T e x t a f t e r t e s t 00186bf linux $
In particular holes can cause problems when a program tries to read the data via the file system - it is nearly impossible to tell which nulls were written to disk or not ([Zwicky, 1991]), and the size of the file read and what is actually stored on the disk can be quite different. Programs that can bypass the file system (such as dd and dump) have no problems with holes, but when using the normal file system interface to copy or read the file additional null bytes will be read and the result will be larger than what is actually on the disk.
Below the abstraction of inodes and data blocks lies the abstraction of zones, labels, and partitions. The typical UNIX disk partition is organized into equal-sized zones (see figure 3.3). Typical zone sizes are 32768 blocks; the block size depends on file system type, and with some systems it also depends on the file system size. UFS, FFS and Ext2fs use a block size that is a multiple of 1024 bytes.
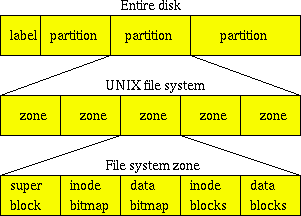
Figure 3.3: On-disk layout of a typical UNIX file system. Figure is not drawn to scale, and files may appear larger in your rear-view mirror than they do in real life.
Storage space is divided up into multiple zones, each of which has its own copy of the superblock, allocation bitmaps, file data blocks, and file attribute (inode) blocks. Normally, information about a small file is stored entirely within one zone. Disk labels hold disk geometry data about its cylinders, tracks, sector, and partition layout
Excessive disk head motion is avoided by keeping related information closely together. This not only reduces the fragmentation of individual file contents, it also reduces delays while traversing directories in order to access a file. Good file system locality can be expected to happen with any file system that doesn't fragment its information randomly over the disk. The TCT program Lazarus takes advantage of this property when attempting to reconstitute the structure of deleted or lost file system data.
When data is accessed or modified through the file system evidence of the activity may exist in MACtime bits or in any system or kernel accounting. Instead of modifying a file through the file system, however, you may modify the data blocks by writing directly to the device that contains the data in question, to bypass the file system in order to avoid leaving behind traces of file access. You'll remember that we used fls and icat to read underneath a file system; the program in listing 3.3 modifies data by directly accessing the disk device itself and change logs that might register an attacker's presence. It does so by reading until it sees the attacker's system name ("evil.fish.com") and replacing this with an innocuous log entry ("localhost"):
#
# Usage: "program device-file"
#
# open the device or file for both reading and writing
open(DEVICE, "+<$ARGV[0]") || die "can't open $ARGV[0]\n";
# make sure the change is the same length!
$TARGET = "connection from \"evil.fish.com\"";
$MUTATE = "connection from \"localhost\" ";
$BYTESIZED = 4096;
$n = $position = 0;
while (($num_read = read(DEVICE,$block,$BYTESIZED))) {
if ($block =~ /$TARGET/) {
$current = tell(DEVICE);
$block =~ s/$TARGET/$MUTATE/g;
seek(DEVICE, $position, 0) || die "Can't seek to $position\n";
print DEV $block;
seek(DEVICE, $current, 0) || die "Can't seek to $position\n";
}
$n++;
$position = $n * $BYTESIZED;
}
Listing 3.3: Those with guts - or using someone else's system - can
bypass the file system with this Perl program.
Only those who are a bit carefree or on death row should attempt this with any regularity, as serious file corruption could happen when the program and the system race to write to the same block. Intruders, of course, might not care about your data as much as you do.
Unless your logs or files are kept in multiple locations or on different hosts, low-level countermeasure like FreeBSD's securelevel(7) (see section 5.6, "Protecting forensic information with kernel security levels", for more about this) are required to truly defend against this sort of obnoxious behavior. It can be detected, but even that may be difficult. Files may be compared with backups that have been saved either entirely off-line or on a different computer. Performing digital signatures on individual blocks of files is another way - you know that last week's records of log file, for instance, should rarely be changing after the events in question - but is very cumbersome to perform in practice. [Schneier, 1998] describes a method of protecting log files so that intruders cannot read or undetectably modify log data that was written before the system was compromised - but of course, you must have this type of mechanism in place before any incident occurs.
Data may be kept from disclosure or undetected modification by utilizing encryption, but in a rather unusual approach the Steganographic File System ([Anderson, 1998]) goes even further. The Steganographic File System is a way of hiding data by encrypting the data and writing it multiple times to random places on a disk. It not only keeps the data encrypted but provides plausible mathematical deniability that data is even there. It also provides has multiple layers of encryption, where the unused blocks of layer N may contain the data of a hidden file system N+1. This means an investigator cannot find out if all the keys for all the levels have been surrendered. StegFS ([McDonald, 1999]), a modified implementation of the system, uses unallocated blocks of an Ext2fs file system to hide its data.
We've travelled up and down the file system, but there are still a few dark corners we haven't visited yet. Most UNIX computers never utilize significant amounts of space on a disk even if it is reaching "full." This is mostly due to the layers of abstraction that we've laid on top of the underlying disk - many of the things that make systems easier to use also sacrifice a bit of performance and introduce some amount of waste. For normal usage this may be easily ignored - when you have a terabyte of storage or more what does it matter if some amorphous gigabytes are wasted or unaccounted for? However, for someone with something to hide, the more capable a system is, the faster it is, the more space it has to store data, the easier it is to conceal information and programs - as well as it is harder to detect. And while some methods give more room than others, all give plenty of room for malware and hidden data to rest comfortably.
Although UNIX file systems have an efficient set of algorithms that prevent serious fragmentation or waste of space under most situations, there will be a certain amount of overhead and waste in any file system. Since UFS, FFS and Ext2fs will not write data to the disk in multiples of less than their block size, any file that doesn't have a size in an exact multiple of the block size will have a bit of unused room (often called slack space) at the end of the data block. With a block size of 1024 bytes a file will, on average, waste 512 bytes of space - about 50 megabytes for each 100,000 files. The bmap [Ridge, 2002] tool can read, write, and wipe data in the slack space at the end of Ext2fs files.
When a UFS, FFS or Ext2fs file system is created by newfs it reserves about 3 percent of the disk blocks for use by inodes. This is a one-size fits all scheme, however - there are only so many inodes to go around, and once you're out you cannot create files or new inodes. For the vast majority of systems this is more than enough - however, this also means that the majority of inodes are never used. When we examined some 70 UNIX workstations we found that about 2.5% of the inodes were used (and only one system used more than half its maximum inodes.) This means that in a 100GB file system there will be about 3 GB of virgin territory that will never be touched by the file system.
We've already seen how entire disks or partitions may be hidden or unused, and how to detect this with fdisk or prtvtoc. However, there is often sometimes a bit of space left over between disk partitions or at the tail end of a disk that may also be used for hidden storage. Swap files or swap partitions may also be used as a potential cache, for as memory chips have lowered dramatically in price and likewise increased in storage space swap is probably being used less frequently, and could be used for some time without being overwritten.
The basic hierarchical file system model used by UNIX (and other) file systems has proven to be remarkably resilient and adaptable over the years, and we foresee it continuing to be so for some years to come.
Some might wonder why we talk about various minutiae concerning UNIX file systems when what you really want for post-mortem analysis is to copy the entire disk with a low-level software program such as dd or via a hardware solution. The file system abstraction is not only useful in day to day operations of a computer, but also when performing an analysis on a system, as we shall see in the next chapter, "File System Analysis." In addition, content-based examinations may easily be derailed by data that has been encrypted, compressed, or simply fragmented into various pieces over the disk.
As reported elsewhere ([Miller, 2000] and [Zwicky, 1991]), UNIX system tools are prone to have unexpected failure modes that result in inaccuracy or even corruption of information. Given the need for accuracy and the often serious nature of investigations, that file systems and forensic tools appear to be no different is even more alarming. Our own work is not immune - while writing this chapter we discovered (and fixed) some problems in our own forensic software, TCT; presumably there are more problems and issues as yet discovered. As people try to push these complex systems to their limits - and beyond - things will break unless we are very careful indeed. Tread lightly and keep your eyes open.
[Anderson, 1998] Ross Anderson, Roger Needham, & Adi Shamir
"The Steganographic File System". 2nd Information Hiding Workshop, 1998.
http://www.cl.cam.ac.uk/ftp/users/rja14/sfs3.ps.gz
[Card, 1994] Remy Card, Theodore Ts'o, Stephen Tweedie,
"Design and Implementation of the Second Extended Filesystem".
Proceedings of the First Dutch International Symposium on Linux,
Amsterdam, December 8-9, 1994.
http://web.mit.edu/tytso/www/linux/ext2intro.html
[Carrier, 2004] Brian Carrier, TASK (Sleuth Kit):
http://www.sleuthkit.org
[McDonald, 1999] Andrew D. McDonald, Markus G. Kuhn,
StegFS: A Steganographic File System for Linux, to appear in the
proceedings of Workshop on Information Hiding, IHW'99, Dresden,
Germany, Sept. 29-Oct. 1, 1999, LNCS, Springer-Verlag.
http://www.cl.cam.ac.uk/~mgk25/ih99-stegfs.pdf
[McKusick, 1984] Marshall K. McKusick, William N. Joy, Samuel J.
Leffler, and Robert S. Fabry, "A Fast File System for UNIX". ACM
Transactions on Computer Systems 2, 3 (August 1984), 181-197.
http://docs.freebsd.org/44doc/smm/05.fastfs/paper.pdf
[McKusick, 2005] Marshall K. McKusick and George V. Neville-Neil, The Design and Implementation of the FreeBSD Operating System. 2005, Pearson Education, Inc.
[Miller, 2000] Barton P. Miller et al., "Fuzz Revisited: A Re-examination of the
Reliability of UNIX Utilities and Services", February 2000, Computer
Sciences Department, University of Wisconsin, 1210 W. Dayton Street,
Madison, WI 53706-1685, USA.
ftp://grilled.cs.wisc.edu/technical_papers/fuzz-revisited.ps
[Nemeth, 2001] Evi Nemeth, Garth Snyder, Scott Seebass, Trent R. Hein, et al., "Unix Administration Handbook, 3rd Edition". 2001, Prentice Hall.
[Nemeth, 2002] Evi Nemeth, Garth Snyder, Trent R. Hein, et al. "Linux Administration Handbook", 2002, Prentice Hall.
[POSIX, 2004] For more on the POSIX and POSIX.1 standards,
see the FAQ:
http://www.opengroup.org/austin/papers/posix_faq.html
[Ridge, 2002] bmap was written by
Daniel Ridge. A discussion on how to use it:
http://www.linuxsecurity.com/feature_stories/data-hiding-forensics.html
[Ritchie, 1974] D.M. Ritchie, K. Thompson, "The UNIX
Time-Sharing System". Communications of the ACM, 17, No. 7 (July
1974), pp. 365-375.
http://cm.bell-labs.com/cm/cs/who/dmr/cacm.html
[Schneier, 1998] B. Schneier and J. Kelsey,
"Cryptographic Support for Secure Logs on Untrusted Machines", The
Seventh USENIX Security Symposium Proceedings, USENIX Press, January 1998,
pp. 53-62.
http://www.counterpane.com/secure-logs.html
[Zwicky, 1991] Elizabeth D Zwicky, "Torture-testing Backup and Archive Programs: Things You Ought to Know But Probably Would Rather Not", Lisa V Proceedings, San Diego, CA. Sep. 30-Oct. 3, 1991.