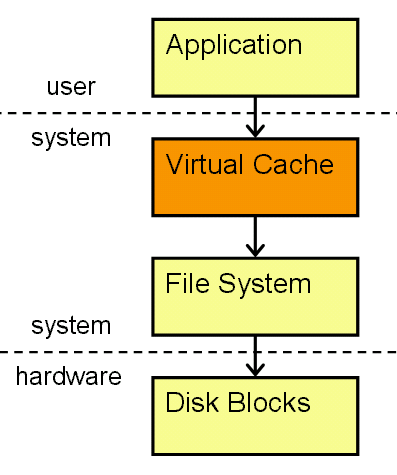
Figure 8.1: Contemporary file system caching.
Thus far we've covered only elementary aspects of memory as well as how to conduct basic analysis of processes. However, the tools we've seen only give access to memory of a running process - they're useless once it terminates. Here we'll be moving beyond the process abstraction and start investigating a computer's virtual memory (VM) subsystem.
In this chapter we'll be finding and recognizing content and files from raw memory, exploring how long information can be expected to survive in main memory on a running computer, and investigating what factors contribute to a computer's amnesia. The main problem faced here is the great variation of the internals of how memory is implemented, not only from one operating system to next, but with even minor releases of the same memory manager. This means that system-specific techniques will have high development and learning costs as well as a short shelf life.
To make the problem less quixotic we'll restrict our discussion to a general-purpose machine architecture where programs and data are stored in permanent files and where programs and data must be copied from file store into main memory in order to be executed or processed. This is unlike various special-purpose architectures (such as those found in many PDAs, cell phones and the like) that store programs and data in directly-addressable memory locations so they don't need to be copied into main memory to be used.
After an introduction of the basics of virtual memory and of memory capturing techniques, we show how information in memory may be identified using digital hashes, how the decay of memory content is influenced by properties of the computer system architecture (including decrypted content from the Windows encrypted file system), and conclude by looking at its resilience to destructive forces.
All modern operating systems use virtual memory as an abstraction to handle combinations of RAM (or what we'll call main memory), swap space, ROM, NVRAM, and other memory resources. The memory manager, which runs in the kernel, handles the allocation and deallocation of the memory on a computer - including what is used by the kernel itself. The file system has always been cached to some degree, but eventually all the operating systems we discuss in this book went to a unified caching scheme that marries the file system cache with the rest of the VM system. This not only means that they share the same memory pool but that the performance of the file system (one of the major drains on system performance) is greatly enhanced. Figure 8.1 illustrates the layers between an application and the actual data on the disk.
Figure 8.1: Contemporary file system caching.
The VM system is organized into fixed size blocks of data called pages which in turn are mapped to actual physical addresses of memory; it gives a simple and consistent virtual address space irrespective of the underlying physical memory setup. It also dynamically loads only the portions of a program file that are required for execution, instead of the entire executable file, and supports the sharing of memory between processes that use the same data or program code.
In this chapter there are three classes of memory we'll be most concerned with - that used by the kernel, processes, and buffers. The UNIX VM provides a unified way of allocating memory for these areas, with nearly all free memory (e.g. memory not used for processes or the kernel) being allocated for caching or buffering of files. This caching is why an initial operations that use the file system can take a significant time, but subsequent usage of the same data may be much faster, as the I/O takes place in memory rather than on disk. It's also crucial to note that these file system buffers are owned by the operating system, and not by user level applications that access files. Consequently, file content remains cached in main memory even after any requesting application has terminated.
If a piece of memory is not directly associated with a file or the kernel it is called anonymous, and when the VM manager runs low on main memory it may use swap space as a secondary location for anonymous memory. Swap is nearly always stored on disk, and has significantly less performance and slower access speeds than main memory. We have found in our measurements, however, that modern computers swap less and less as memory has gotten larger and cheaper. This is both bad and good news for forensic analysts - bad because swap is more persistent than main memory and is used less, so the odds of it having useful information is smaller. But it may also be good also because once data has been placed into swap it can stay there for some time.
Demand paging is an efficiency measure that means that memory pages are only allocated as referenced (e.g. actually used), which significantly reduces the memory footprint as well as lowers the startup time of processes. Consider the output from ps:
The VSZ is the virtual size of the processes - i.e. how many kilobytes the VM has allocated for it. RSS stands for the Resident Set Size of a process, and is how many kilobytes of the process is actually in memory. Notice how even an identical program (in this case the bash login shell) may have different sizes of virtual and resident memory. This is because as even identical programs run they may dynamically allocate anonymous memory, use demand paging when executing different parts of the program, or swap in different ways and at different times.linux % ps ux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND zen 6201 0.0 0.1 2140 1336 pts/0 S Dec22 0:00 -bash zen 12837 0.5 0.1 2096 1268 pts/1 S 15:04 0:00 -bash zen 12855 0.0 0.0 2668 952 pts/0 R 15:04 0:00 ps ux
Computer systems organize memory into fixed-size pages just as they organize file systems into fixed-size disk blocks. A page is the smallest unit of data that may be allocated by a system's VM manager, and is generally 4096 or 8192 bytes long (although some architectures will support memory page sizes of 4 MByte or more this won't affect our discussion; the concepts are the same. The getpagesize() library function will return the size of a memory page. Solaris and FreeBSD systems can also print out the memory page size with the pagesize command.)
To better understand how to find information in memory, we need to understand what data sits in memory pages and how. There are two basic types of data, that read from files and the anonymous pages that contain state data from processes (alive or dead) or the kernel. The VM manager decides if a page is backed by a file, physical memory, or swap, depending on its needs and the type of data involved.
Any memory page that originates from a file has special status within memory due to the aggressive file caching strategies used by the VM manager. Files may also be memory mapped, which means that changes to a memory page in main memory will also change the corresponding bytes in a file. In any case once a file has been read into main memory its data will remain for some time, depending on how busy the computer is after the event.
A process consists of a set of executable statements, usually from a file. A process is allocated a certain amount of memory that it sees as a seamless virtual address space, whether or not it's contiguous in the memory pages of actual memory. To recapitulate, figure 8.2 shows the virtual view that a process has of itself.
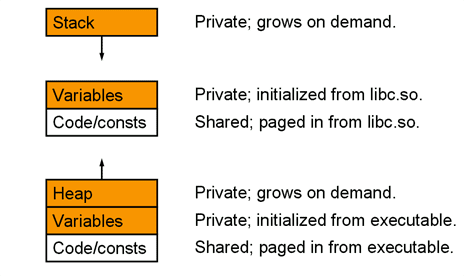
Figure 8.2: The address space of a process
The parts labeled private are swappable, but shared bits are taken from the file system and don't need to be swapped. All of our example systems have reasonably nice methods of displaying how individual processes rest in memory. FreeBSD has the /proc/[pid]/map file, Linux /proc/[pid]/maps, and Solaris the pmap command.
Pages that aren't associated with a file compose the electronic flotsam and jetsam of memory. These include process or kernel state data - the heap, stack, etc. Most data here is in no discernible format whatsoever - unless you know the data structures that the individual programs use to save arbitrary data in memory.
Anonymous data can be long-lasting, but tends to be much more volatile than file data because it isn't cached like files are. We'll be looking more at anonymous pages in "The persistence of non-file or anonymous data" section later in the chapter.
Before we can begin analyzing memory we need to capture it - or, at least, as much as we are able to. In addition to the savecore program we'll look at the three primary locations that UNIX systems interface with memory - the /dev/mem and /dev/kmem special devices, swap, and the various peripherals and hardware that have memory capacity (NVRAM/PROMs/etc.)
Determining the available amount of main memory and swap space is easy with the top command. If top isn't available there are a variety of ways to this find out on any given operating system.
Solaris has the prtconf print system configuration utility and the swap command:
solaris # prtconf |grep -i 'memory size' Memory size: 768 Megabytes solaris # swap -l swapfile dev swaplo blocks free /dev/dsk/c0t0d0s1 32,1 16 304544 298144
FreeBSD has sysctl, which can print and configure the kernel, and pstat to display system swap characteristics:
freebsd # sysctl hw.physmem hw.physmem: 532013056 freebsd # pstat -s Device 1K-blocks Used Avail Capacity Type /dev/rad0s4b 1048448 0 1048448 0% Interleaved
Linux can use the /proc memory file system and kcore to get memory and swap size information:
linux # ls -l /proc/kcore -r-------- 1 root root 1006637056 Mar 22 12:24 /proc/kcore linux # swapon -s Filename Type Size Used Priority /foo/swapfile file 1999992 4092 -1
(kcore is actually 4KB larger than the actual physical memory size.)
The Heisenberg property of computing (see section 1.4, "The Order of Volatility") reminds us, however, that by using software to capture memory we're also disturbing the current memory image by executing a program and reading in data. Writing the results of your memory capture presents another problem. The unification of file buffers into VM means that any file output will be cached in memory, replacing the very information that you are trying to capture! Using a remote computer may be the best way to save data with minimal memory mutilation; we'll talk more about this in the device file section below.
All this means that anytime you want to save memory it can be a bit of a conundrum - you want to preserve this very volatile data early on in a forensic investigation, but saving it can destroy additional evidence. What to do? While there is no 100% guarantee, as a rule of thumb if you suspect something of interest is on the computer we suggest you attempt to capture as much memory as you can - even if does mean risking some damage done to other evidence.
Many computers (especially laptops) have a hibernation mode that will store varying amounts of main memory and computer state on its disk. Hibernation mode sounds promising: simply copy the data from the disk, restore the computer to its previous state, and go on with your analysis. Unfortunately, unallocated memory (which is important for our analytic methods) isn't usually saved. To make matters worse, hibernation mode frequently stores memory in some compressed or ill-documented format. And while you should use any method that is available in this chapter we'll focus on pure software methods to capture memory.
Most flavors of UNIX have the savecore command to help save a dump of some, if not all, of the computer's main memory (as of this writing Linux doesn't have this capability, although some distributions and patches do exist to allow this.) This is one of the more attractive options to save memory with, as it bypasses the file system and should disturb memory the least. The savecore program instructs the kernel to write memory directly to swap or a designated raw disk partition, after which (usually upon reboot) the savecore program may be called to recover the core dump and store it in a regular file system. The core dump contains the kernel's memory and either the process memory or all of main memory.
The computer must also be set up properly for dumping before savecore may be used. To manage the savecore process FreeBSD uses the dumpon command while Solaris has dumpadm, but as far as we know only Solaris can do the very useful running of savecore on a running system without requiring a reboot, as shown in listing 8.1.
solaris # dumpadm
Dump content: all pages
Dump device: /dev/dsk/c0t4d0s1 (dedicated)
Savecore directory: /foo/savecore
Savecore enabled: yes
solaris # savecore -v -L
dumping to /dev/dsk/c0t4d0s1, offset 65536
100% done: 16384 pages dumped, compression ratio 2.29, dump succeeded
System dump time: Mon Dec 30 14:57:30 2002
Constructing namelist /foo/savecore/unix.1
Constructing corefile /foo/savecore/vmcore.1
100% done: 16384 of 16384 pages saved
solaris # ls -asl /foo/savecore/
total 264354
2 drwxr-xr-x 2 root other 512 Dec 30 14:57 ./
2 drwxr-xr-x 4 root root 512 Oct 22 22:44 ../
2 -rwxr-xr-x 1 root sys 2 Dec 30 14:58 bounds*
704 -rw------- 1 root sys 349164 Dec 30 14:57 unix.1
263472 -rw------- 1 root sys 134905856 Dec 30 14:58 vmcore.1
Listing 8.1: Saving the kernel memory core dump via savecore.
The kernel's symbol table was stored in unix.1, main memory in
vmcore.1.
Crash dumps of memory on Solaris and FreeBSD may also be forced with the -d flag to the reboot command1. Obviously this can be damaging to other types of forensic evidence, but it might still be useful.
Footnote 1: Microsoft's Windows XP and Windows 2000 operating systems may set a registry variable that allows a computer to dump up to two gigabytes of RAM by using a Ctrl-ScrollLock keyboard sequence (Microsoft Knowledge Base Article 244139: Windows 2000 Memory Dump Options Overview). This is similar to FreeBSD's reboot command, but it has the added disadvantage of requiring an additional reboot of the system in advance in order to enable this. (Some other UNIX computers allow you to dump memory in a similarly destructive manner, such as typing Stop-A or L1-A on a SUN console, followed by the sync command.
FreeBSD systems or older versions of Solaris can use options to commands like ps, netstat, ipcs and the like to directly query a saved memory image, allowing you to see what was running at the time of the dump. Solaris tools have been constantly evolving; currently it has the mdb command which improves on the functionality of the older tools, while the more ambitious MemTool [MEMTOOL, 2004] and Solaris Crash Analysis Tool [SCAT, 2004] are available online. In the right hands a saved crash dump paired with the right tools can reveal volumes, and retrieving such things is outside the scope of this book (for a better, albeit a bit dated discussion of this, see [PANIC, 1995]).
Memory device files - /dev/mem and /dev/kmem
If savecore isn't practical there are other methods to capture memory. Accessing the memory of a system is easy if you have sufficient user privileges - UNIX systems permits you to read or write to memory via the /dev/mem or /dev/kmem device files. /dev/mem is a special file that mirrors main memory - byte offsets in the device file are interpreted as memory addresses by the kernel. /dev/kmem represents the virtual (rather than physical) address space of the kernel, presenting a more uniform view of the memory in question.
Merely trying (say) cat or dd on memory device files to capture memory won't work very well on many systems, however. For instance the FreeBSD /dev/mem implementation (currently) doesn't return an EOF (End Of File) when it reaches the end of physical memory. Solaris, on the other hand, might not start at address 0 or have holes in the memory mapping if it isn't using maximum-sized memory chips, which means that you'll get either nothing or an incomplete version of the system's memory 2
Footnote 2: Microsoft Windows users can try George Garner's port of dd to capture physical memory [GARNER 2003].
The memdump program was written to avoid such problems (it can be found at the book's website.) It was designed to disturb memory as little as possible and use a minimum of memory when running.
Using memdump, Solaris' ability to save memory without rebooting, or any other method to save memory to disk, is not without forensic flaws. Writing the data to any device - swap, unused, or one containing a file system - can potentially compromise forensic data. Perhaps the best solution - and the one we recommend - is to use the network as a storage facility. While there will be some memory agitation, you can try to keep it to a minimum. Red Hat Linux, for instance, introduced a network version of a crash dump facility [REDHAT] that runs on their advanced server that sends the memory dump over the network rather than saving it to the local disk. Simply using a good capture method with a tool like netcat can provide a reasonable way of saving the memory of a running computer:
solaris # memdump | nc receiver 666
Unless on a trusted LAN this would ideally be piped through a program that would encrypt the data, or perhaps sent through an encrypted tunnel (e.g. ssh), as the memory dump could contain sensitive information (see chapter 4, "File System Analysis", for more on this.)
|
Side bar: The Quick-and-Dirty Way to Capture Memory
While we advocate using a special-purpose program like memdump you might run into a situation where you don't have or have turned off access to the Internet after an incident, fear the disturbance of downloading a program and compiling it, or perhaps don't even have a working compiler installed. In those situations you may capture a goodly amount of raw memory from a computer by using a simple program that cycles over its memory address space one memory page at a time. And while Perl and other scripting languages don't have particularly small memory footprints (and thus destroy some memory when run), this Perl program illustrates how a few lines of code can capture most of a computer's memory.
This program can then be used with Netcat to send the memory to a waiting remote system (in this case, "receiver".) freebsd # ./dump-mem.pl 512 | nc -w 5 receiver successfully read 536870912 bytes freebsd # |
Swap space
We've already seen how to find the swap devices of a system (in the "Capturing Memory" section), and it is the easiest type of memory to copy of them all - simply cat or dd the device or file in question. Again, writing it to the network (via netcat or other means) is the preferred method of saving the results.
Other memory locations
System peripherals (graphics boards, disk drives, etc.) often have memory, and sometimes in large quantities. If they show up as a device in the file system (most often in the /dev directory) then simply using cat(1) can be enough to capture the memory. Unfortunately this isn't the norm, as almost every device uses a different method to access and store memory. Alas, it is outside the scope of this book about how to retrieve such device memory.
It's fairly simple to use peripheral memory to stash data or programs. Michal Schulz wrote an article [SCHULZ, 2002] about how to use a video card's unused memory to create a UNIX file system as a RAM disk.
Finally, in a literal outside-the-box way of thinking, virtual machines (VMware, Virtual PC, etc.) can be quite useful as tools to capture a system's memory, especially in laboratory or testing situations. Often a virtual machine simply runs as a regular process and its entire memory space can be captured with a command such as pcat, although some programs will only map a slice of the entire memory space at anytime for efficiency.
Data from files gets into memory by either by being executed or otherwise read by the operating system. Perhaps the simplest way to find useful data in captured memory (i.e. via pcat) is to use either a directed search of known content (e.g. grep(1)), to brute force recognized text (e.g. strings(1)), or with a combination of the two. If you're trying this out on a running system you must exercise a tiny bit of care to ensure that you don't find the string you're searching for as the search string gets loaded into memory itself:
freebsd # ./dump-mem.pl > giga-mem-img-1 successfully read 1073741824 bytes freebsd # strings giga-mem-img-1 | fgrep "Supercalif" freebsd # cat helloworld Supercalifragilisticexpialidocious freebsd # ./dump-mem.pl > giga-mem-img-2 successfully read 1073741824 bytes freebsd # strings giga-mem-img-2 | fgrep "Supercalifr" Supercalifragilisticexpialidocious Supercalifragilisticexpialidocious freebsd #
This command sequence demonstrates that the entire file containing the string "Supercalifragilisticexpialidocious" is small enough so that it is unlikely to be broken across page boundaries and is easily found.
Several file systems now have the capability to encrypt all or part of their content. Windows XP Professional, for example, has a fairly easy to use file system encryption feature that may be turned on a per file or per directory basis. This is often set by the windows explorer property dialog.
When a directory has the encryption feature turned on, any file created in that directory will be stored encrypted. This is very different from encrypting a file after it is created as cleartext. The main difference is that no cleartext data is written to the file system, so that it cannot be recovered by reading the raw disk.
Creating an encrypted file
For testing purposes we used a Windows XP Professional system with 160 MByte of memory that runs inside VMware. A folder (c:\temp\encrypted) was set up with the property that any files created there be encrypted. A file was downloaded into this directory via FTP. The file simply had lines starting with a number followed by text - e.g.:
00001 this is the cleartext 00002 this is the cleartext 00003 this is the cleartext ..... .. .. . .. .. 11934 this is the cleartext 11935 this is the cleartext 11936 this is the cleartext
There were a total of 11936 lines of text for a total of 358080 bytes.
The file system encryption appeared to do its job. After downloading the above file into the encrypting directory, a quick search of the raw disk did not turn up traces of the original cleartext. This search for plaintext data was relatively easy because the Windows disk was accessible as an ordinary file from the UNIX operating system that VMware was running on.
Recovering the encrypted file from main memory
As we've seen in this chapter, the disk is not the only place where file content is found. In order to access a file, its content is copied into main memory. In order to improve system performance, recently (or frequently) accessed file content stays cached in main memory for some amount of time, depending on system usage patterns.
All this applies to encrypted files too: at some point the content of our target file had to be in decrypted form and copied into main memory. The unencrypted content remains cached for some amount of time that depends on system usage patterns. Just how long, and if the data persisted once the user logged off, was our concern.
There are several ways to access the main memory of a Windows system. We used the previously mentioned Ctrl-ScrollLock keyboard hot-key sequence (Microsoft knowledge base article 254649). Once it is enabled, anyone with access to the keyboard can request a memory dump, even without logging into the machine. The resulting dump file was transferred to a UNIX computer for simple string analysis:
freebsd # strings memory.dmp | grep 'this is the cleartext' | wc (lines) (words) (bytes) 20091 120547 582564
Obviously, 20091 lines is a lot more than the 11936 that were in the original file, so some information was present more than once. Elimination of the duplicates showed that practically all the unencrypted content could be recovered from the memory dump:
freebsd # strings memory.dmp | grep 'this is the cleartext' | sort -u | wc (lines) (words) (bytes) 11927 71567 345848
Of the 11936 lines of cleartext, 11927 were recovered from main memory.
Windows file encryption provides privacy by encrypting file content before it is written to disk. This is good, because the unencrypted content cannot be recovered from the raw disk. However, unencrypted content stays cached in main memory, even after the user has logged off. This is bad, because the unencrypted content can still be recovered from raw memory. The cached data will decay over time, according to the usage patterns of the system, but the multiple copies of the data present in memory will only add to the time that it persists.
This is presumably counter to expectation, and hopefully of design. At a minimum, once the user logs off, not only should any decrypting key information be purged from main memory, the cleartext content of files should be purged from main memory also.
Since a significant portion of what is loaded into memory comes from the file system, we can identify portions of memory by comparing it with what is in a file system. The structure of memory makes this easier - we know where the data starts and the boundaries of where the data lives as well as how big the page-sized chunks of data are, so we can simply break the raw blocks of a file system into similarly sized chunks and do a brute force comparison against all the pages in memory. While a match - or miss - aren't 100% indicators that the memory page actually came from a given file system or not, it does identify the memory page with certainty, which for our purposes is equally important. Executable files in memory might prove to be somewhat problematic to spot since they can be broken into pieces in memory; we'll examine that problem in the next section.
Table 8.1 shows a slightly more efficient method of comparing the MD5 hashes of all the pages in memory against the MD5 hashes of the raw disk. VMware was used to easily manipulate the available memory of the test systems, and the measurements were taken immediately after the system was started.
Megabytes of Memory % Page Matches MB % NULL pages MB % Unrecognized MB FreeBSD 5.0 + KDE 2.1 128M 20.6% 26.4M 44.3% 56.7M 35.1% 44.9M 192M 19.9% 38.2M 53.0% 101.8M 27.1% 52.0M 256M 11.7% 30.0M 73.3% 187.6M 15.0% 38.4M 384M 8.6% 33.0M 79.9% 306.8M 11.5% 44.2M SuSe 7.1 + KDE 2.1 128M 31.2% 39.9M 32.3% 41.3M 36.5% 46.7M 192M 20.7% 39.7M 56.0% 107.5M 23.3% 44.7M 256M 15.9% 40.7M 65.8% 168.4M 18.3% 46.8M 384M 12.9% 49.5M 74.4% 285.7M 12.7% 48.8M Solaris 2.51 + OpenWindows 128M 39.3% 50.3M 15.3% 19.6M 45.4% 58.1M 192M 37.6% 72.2M 15.0% 28.8M 47.4% 91.0M 256M 37.3% 95.5M 13.1% 33.5M 49.6% 127.0M 384M 38.4% 147.5M 16.3% 62.6M 45.3% 174.0M Table 8.1: Recognizing content in memory using MD5 hashes of 4096 byte blocks and memory pages (Intel x86 versions of the OS's.)
The large number of null memory pages found are because system has just started and hasn't written any data to most of the memory pages yet; the number of actual memory page matches generally rises due to the file system being cached according to how much memory is available. By itself this is of limited use, but we'll use the page-block matching technique throughout the chapter in a variety of situations for measurements and observations.
The percentages of identified files varies significantly depending on what the computer does and has been doing lately. For instance, using large portions of memory for calculations or database manipulation can easily fill main memory with data that isn't from files and is hard-to-recognize. Still, measuring live or production computers we routinely identified 60 or 70% of the memory space, and in one case identified over 97% of the memory pages for a system with a gigabyte of memory.
Since files are placed into memory pages, another way to find a specific file containing the aforementioned word "Supercalifragilisticexpialidocious" would be to take the MD5 hash of the file (null padding it to correspond to the size of a memory page when needed) and compare it to all the MD5 hashes of all the pages in memory. The memory page that contained the word would have the same MD5 hashes as the file. This method would only find small files, however - those that fit into a page of memory. And it might well fail to find executables associated with even very small processes, since the image associated with the file isn't always stored in a contiguous space in memory.
Of course we can break files into page-sized pieces in the same manner that we did with the raw disk. If we take the MD5 hashes of every page-sized chunk of every file on a computer's file system and compare them to the MD5 hashes of every page of memory a match means that that file - or one with a slice of identical data - has been loaded into memory.
The result of such a brute force approach is something like a ps command that finds the executable and library files, directory entries, and any other file that are currently in main memory. They may be in use - or simply in memory from being used in the past, there is no way of finding out using this method. Since files - or portions of files - may not be currently in memory even while being used by the system (a sleeping process, a file that is open but not accessed in some time, etc.), this might be a modestly non-reliable way of reporting memory usage, but it can give information that is difficult if not impossible to get using traditional methods.
Here we use this method to see files accessed during a compiler run, served up by the web server, mail folders opened, and the like. The results in listing 8.2 are something akin to a very ephemeral MACtime tool (a program that is part of the TCT software package; see appendix A for more information) that only shows that a file has been read or written to.
/kernel (80.7% found, 3814504 bytes) /modules/ng_socket.ko (84.6%, 12747) /modules/ng_ether.ko (81.8%, 10899) /modules/ng_bridge.ko (84.6%, 13074) /modules/netgraph.ko (94.7%, 38556) /modules/linprocfs.ko (92.8%, 27843) /var/run/ppp (100%, 512) /var/run/syslog.pid (100%, 3) /var/run/dev.db (25.0%, 65536) /var/run/ld-elf.so.hints (100%, 203) /var/log/sendmail.st (100%, 628) /var/log/auth.log (66.7%, 15345) [... 500 more lines omitted...]Listing 8.2: A snippet of user files currently in memory, this time found by comparing MD5 hashes of 1024 byte pieces of files against the memory pages in a computer running 4.6 FreeBSD.
You'll often see only parts of larger files in memory, for the data is only loaded as it is accessed.
In our measurements collisions - two or more page-sized disk chunks that have the same content, and therefore the same MD5 hash - occurs roughly in about 10% of the time when comparing file blocks. While this might sound rather high, in practice collisions are fairly rare and tend to concentrate over certain popular values (a block containing all NULLs, for instance, is rather popular). Most of the uninteresting results can be removed simply by listing all the files that could possibly match or by using a threshold scheme where a file has to have a certain percentage blocks in memory before it is identified.
If such methods are to be used in adversarial situations where intruders might modify data it is important to keep the MD5 hash databases off the systems that the measurements are taken from. If saved as text and 4096 byte pages are being used the size of such databases will be a bit less than 1% of the original data, with a few additional percent if file names are also stored, but this could obviously be improved upon.
While not particularly effective this may also achieve some crude level of crude malware detection - rootkit files, program files, exploits, and the like can potentially be spotted in memory, even if they no longer exist on the computer's disks. This begs the question - how long do the echoes of files remain in memory?
Now that we know how to recognize data and files in memory we can measure how long it stays there. Note that unless you look at more than raw memory, or make measurements over time, you can't tell how long it has been there. And because every kernel implements things differently there is no easily obtainable time associated memory metadata about memory (unlike with the file system's MACtimes, for instance.)
We used two primary methods to measure this persistence. The first was to simply capture all the individual pages in memory and measure their change over time. The second was via a program that fills memory with a unique but repeating pattern. It would then deallocate the memory and repeatedly scan /dev/mem for any signs of the previously filled memory. The former was used for some of the longer experiments, while the latter was more useful for spotting rapidly decaying memory.
We first examined fish.com, a moderately busy Red Hat server (handling some 65,000 web requests and email messages per day) with a gigabyte of main memory over a two and half week period. At any given time about 40-45% of its main memory is actually consumed by the kernel and running processes, and the rest is devoted to the file cache and a free memory pool. Every hour memory measurements were sent to a remote computer, and the results are shown in figure 8.3.
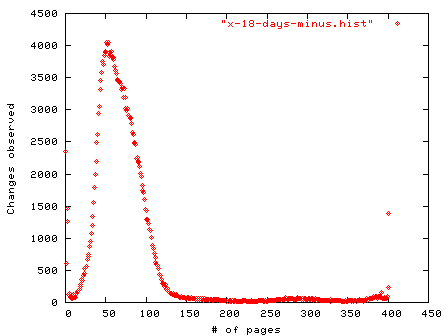
Figure 8.3: Counting memory page changes every hour over 402 hours (16.75 days) using MD5 hashes of memory pages (Red Hat Linux 6.1.)
Obviously some pages changed many more times than we measured in between our hourly measurements. But we saw a page changing 76 times over this 402 hour period, or about every 5 hours. Almost 2,350 memory pages (out of 256,000) didn't change at all (or changed and then changed back), while some 1400 changed with every reading.
Our second case looked at a very lightly used Solaris 8 computer with 768 megabytes of main memory, over 600 of that marked as free, with almost all of that used for file caching. Other than a few administrative logins it was a secondary DNS server that ran standard system programs over a 46 day period; its memory was captured once per day. We've rotated the axis of the graph in figure 8.4 from the previous graph to better illustrate the activity over time.
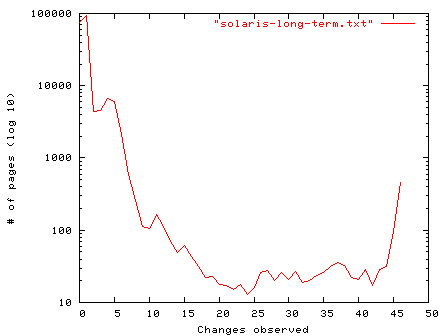
Figure 8.4: Tracking page state changes over 46 days using MD5 hashes of memory pages (Solaris 8 on SPARC architecture.)
This graph shows that very few memory pages changed at all in a month and a half of recording data. The average time between observed memory page changes is 41.2 days, while fully 86% of the memory pages never changed during the experiment and only .4% changed every day.
Unsurprisingly there are great differences in how long memory pages stay around depending on the activity of the computer in question. For seldom used computers data can stay around for a long time. There is more to the story, however - we'll now explore the differences between anonymous memory and file-backed memory pages.
How long files persist in memory strongly depends on the demands placed on resources of the computer involved, the amount of memory in a computer, and many other factors. We can easily determine if a given file is in memory by using our MD5 hash matching method discussed in previous sections. Analyzing the experimental results of fish.com shows about 37,500 pages that corresponded to files were recognized over a two and a half week time period, with the average page not seen changing in memory for 13 hours - a considerable boost over the previously measured 5 hours for pages of all types. While only 8.5% of the files recognized were executable in nature, they were seen in memory for longer periods of time, 20 hours vs. 12 for a non-executable file.
Other than the tools that were used to do the measurements, 84 files were found in every reading, indicating that they were either constantly running during this time or were repeatedly being used. 13 of those were from executable files (mostly system utilities with a couple of user programs):
Of the remaining pages, 53 were taken from libraries (and 29 of those associated with the Apache web server), 18 from Perl modules or support files (8 of those associated with the Spam Assassin anti-spam package), and only two non-executable files - /usr/lib/powerchute/powerchute.ini and /etc/ld.so.cache. At any given time traces of considerable numbers of files were found in fish.com's memory. The average count was 1220, but this varied considerably, going from a low of 135 files to a high of 10,200./bin/hostname /bin/rm /bin/su /bin/uname /sbin/syslogd /usr/bin/perl /usr/bin/procmail /usr/sbin/atd /usr/sbin/crond /usr/sbin/inetd /usr/sbin/tcpd /usr/local/bin/mutt /usr/local/bin/spamassassin
Figure 8.5 illustrates files being pulled into memory (in this case by a FreeBSD 4 web server.) A file gets loaded, stays for a few hours, and unless it gets requested again goes away as new data is loaded into the cache.
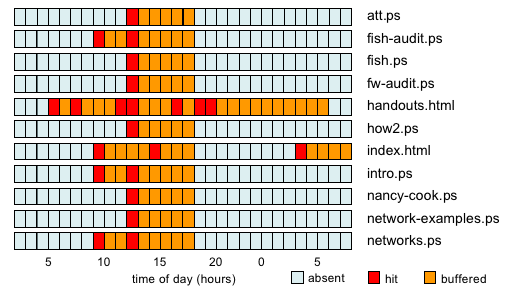
Figure 8.5: File system backed web pages moving in and out of the memory cache.
After a file is deleted, the persistence of memory backed by that file is similar to that of anonymous memory. We've already seen that file data lives longer than what was observed for memory pages, so it's obvious that data not associated with files has a shorter lifespan. How short, however?
Here we used moderately busy FreeBSD 4.1 and Red Hat 6.2 Linux computers. We wrote a program to measure the decay of 1 MByte of private memory after a process exits, repeating the experiment many times and taking the average of the readings. Unlike some of the other measurements taken in this chapter we did not use MD5 hashes, and allowed partial matches of memory pages to capture fragments of memory still remaining because we suspected some VM systems might change pages to store status info. We placed the two measurements on figure 8.6 under another with the same scale, otherwise they would be almost indistinguishable.
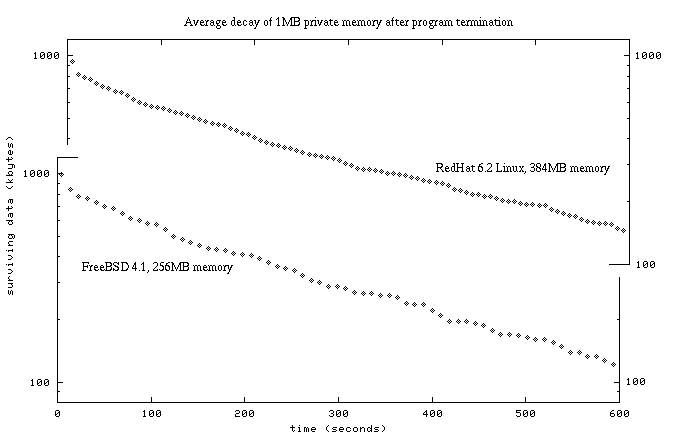
Figure 8.6: Tracking decay of anonymous data in main memory after process termination with memdecay. This program can be found at the book's website.
Don't think that anonymous data slowly and regularly deteriorates, as this graph is the result of many measurements and it gives an artificial smoothness. Instead it remains intact for some time - depending on the activity of the system in question - and then quickly is reclaimed by other processes. In any case after some 10 minutes about 90% of the monitored memory was changed. What's most remarkable is how closely the measurements align, despite entirely different operating systems, memory size, and kernels. Under normal use computers have a fairly rapid and inevitable degradation of anonymous memory pages. This volatility depends greatly on the computer in question, however - for when a computer isn't doing anything anonymous memory can persist for long periods of time. For instance in some computers passwords and other precalculated data were easily recovered days many after being typed or loaded into memory - and in others they were lost within minutes or hours, despite being idle.
For investigators this pattern of decay can be unfortunate, for often the entire point of capturing memory is to try and get the transient data. The aggressive file caching schemes now universally present mean that much of memory is used to store already persistent data for performance reasons. Passwords, a letter a user types in, and other interesting points of data are often the first items to be lost after the process that holds the data terminates.
Swap consists of anonymous data that was once in memory but because of a shortage of system resources has been saved to disk. Since systems swap rarely, information written to swap becomes preserved, or fossilized. Files will not appear in swap (although parts of any file may, if it is used as data) because they are already backed by the file system and there is no reason to save them again.
Memory is so inexpensive that modern computers often have more RAM than is needed for general operations, therefore swapping only when the system is under heavy stress. Such unusual behavior is therefore somewhat likely to leave footprints for some time.
Although most computers automatically zero main memory upon rebooting - many do not. This is generally independent of the operating system; for instance, motherboards fueled by Intel CPUs tend to have BIOS settings that clear main memory upon restart, but there is no requirement for this to happen.
Normally this is of little concern, but when capturing forensic data, and given the potential longevity of data in main memory, it can be important to note this fact. Sun SPARC systems, Apple G4 computers, and others don't regularly clear memory upon reboot (although most may be set to do so via BIOS, EEPROM, or other settings).
The contents of main memory can be perverted or subverted, but it would be very difficult to compromise all the potential sources of information. Any hardware assisted memory dump is nearly impossible to fool without physical access to the computer. This makes hardware assisted memory dumps the most trustworthy, but unfortunately they aren't supported by many systems. Special purpose methods used to dump memory (such as savecore or using keystroke sequences like Sun's L1-A and Microsoft's Ctrl-ScrollLock) perhaps have a slightly higher veracity than a more general source such as /dev/mem if only because of the additional trouble of subverting all such a special-purpose avenues as compared to modifying the kernel's interface to a single file to give out false readings. Swap is usually the most easily modified, as it is stored as a disk partition or even as a file.
You might think that the fragility of memory would mean that it would be relatively easy to clear or fill memory with arbitrary data and thereby frustrate many of the methods discussed in this chapter. This is almost true. For example, this tiny Perl program allocates and fills memory with nulls until it runs out of memory:
# Fill as much memory as possible with null bytes, one page at a time.
for (;;) {
$buffer[$n++] = '\000' x 4096;
}
As the size of the memory filling process grows, it accelerates the memory decay of cached files and of terminated anonymous process memory, and eventually the system will start to cannibalize memory from running processes, moving their writable pages to the swap space. That is, that's what we expected. Unfortunately even repeat runs of this program as root only changed about 3/4 of the main memory of various computers we tested the program on. Not only did it not consume all anonymous memory but it didn't have much of an affect on the kernel and file caches.
Overwriting most of memory, even simply the cached and temporarily saved data turns out to be slightly challenging, as attempts to use higher level abstractions to change low-level data fail. Efforts to read and write either large files or large numbers of files also had limited success. In this case it turned out (ironically?) that by running TCT on a full forensic data gathering run is a pretty good - though slow - way to clear memory. TCT destroys the content of the file cache and main memory by reading many different files and by performing lots of calculations, including an MD5 hash of every file on the entire machine. Even kernel memory is affected, as evinced in table 8.2.
Table 8.2: The effects of activity on memory pages (the average amount of memory changed over three trials.)
Action Solaris 8, 768M Memory SuSe Linux 7.1, 256M FreeBSD 5.0RC2, 192M Running memdump 0.7% changed 5.4M changed 1.2% changed 3.2M changed 0.8% changed 1.6M changed Unpacking, configuring, and compiling TCT 24% 185M 7.6% 19M 17% 33M Writing NULLs to memory once 75% 576M 76% 194M 82% 157M Writing NULLs to memory again 76% 580M 77% 196M 84% 161M Running TCT 98% 749M 95% 244M 91% 174M
If you're concerned with preserving evidence from memory, making a file system backup is the last thing you want to do, for it not only destroys all the file access times but also thrashes all the volatile memory. On the bright side, however, perhaps intruders will start to back up your data after breaking in.
Filling main memory with data from actual files has the added benefit to making analysis and detection more difficult than if someone were to use a fixed pattern to wipe memory. In our testing, however, we couldn't totally eradicate evidence (passwords, pieces of files, and the like) that we planted in memory. In the end, rebooting the computers was the only way to effectively clear memory for most of our computers that reset memory upon reboot. The SPARC and Apple G4 systems had to be physically turned on and off, because they don't reset memory as mentioned earlier.
Whatever method used it can be very difficult to wipe out all traces of activity in main memory. Any program run, anything typed by a user, and all data that breathes on a computer will at some point end up in main memory. While we demonstrate this with a very simple model, Jim Chow et al discuss this topic in significantly more depth in "Understanding Data Lifetime via Whole System Simulation" [CHOW, 2004]. In this paper they discuss how they eliminate much of the guesswork of how information flows by essentially tagging data with virtual colored dyes so that it can be followed in its migration through the kernel, application buffers, network transmissions, and more.
But complex subsystems such as memory management will behave quite differently under the hood on every type of computer and operating system, adding to the difficulty of tricking even our basic techniques, let alone more sophisticated methods. As one of the authors of the data lifetime paper admits, significant analysis of even a single memory systems can take "a group of Stanford systems Ph.D. students more than a few weeks" of time and effort to begin to understand [PFAFF, 2004].
Certainly success at masking or hiding behavior will vary substantially in accordance with the functionality and load of the computer, and of course no single point of forensic data should be absolutely trusted. Even when taken in isolation memory analysis can tell quite a bit about the state of a computer. But it's when correlation is used to tie data taken from memory with data gleaned from other sources - log files, file system and the like - that we can arrive at stronger conclusions.
Because of the page-based virtual memory allocation and file caching schemes used to enhance performance of computers, memory page-based digital signature analysis can find and identify significant portions of memory. String based searches can also be of significant value despite the relatively unstructured and fragmented nature of main memory, as exemplified by our encrypted file system case study.
As with many types of analysis, recognizing or eliminating the known can be a useful method to better understand what's going on in a system. Certainly wading through lots of data looking for clues can be a very dull adventure, and anything that can cut down the work required is a big bonus. And while it can be difficult to find less structured data that is in memory somewhere, if you know what needle you're looking for even a few bytes long may be located in massive amounts of data.
There is a wide variance on how long data persists in memory, not only due to the activity on a computer, but how the memory was stored. File-backed data lasts significantly longer than anonymous data due to the caching of the file data. This means that what most people think of as interesting data is more ephemeral than the already-saved-on-disk data, and if you want to capture the data you should move quickly.
The analysis of memory can reveal significant things about a computer and what it was doing that are nearly impossible to discover using other methods. When investigating a system you should attempt to save as much memory as possible - or, at a minimum, a hash of the memory pages involved. While the latter won't allow you to analyze the unknown content in memory, knowing what was in memory can still be a big advantage.
[CHOW, 2004] "Understanding Data Lifetime via Whole System
Simulation", Jim Chow, Ben Pfaff, Tal Garfinkel, Kevin Christopher,
and Mendel Rosenblum, Proceedings of the 2004 Usenix Security Symposium.
http://suif.stanford.edu/collective/taint.pdf
[GARNER, 2003] The Forensic Acquisition Utilities, including dd,
for Windows.
http://users.erols.com/gmgarner/forensics/
[MEMTOOL, 2004]
http://playground.sun.com/pub/memtool/
[PANIC, 1995] Chris Drake, Kimberley Brown, "PANIC! UNIX System Crash Dump Analysis Handbook", Prentice Hall, 1995.
[PFAFF, 2004] Ben Pfaff, private communication, July 2004.
[SCAT, 2004] Solaris Crash Analysis Tool (Solaris CAT)
http://wwws.sun.com/software/download/products/Solaris_Crash_Analysis_Tool.html
[SCHULZ, 2002] Michal Schulz, "VRAM Storage Device - How to use the memory on GFX board in a different way..." 9/3/2002, Linux News.